
近年の医療領域では、患者の体質や症状の特徴等によって治療の詳細を変える「個別化医療(personalized medicine)」への期待が高まっています。
個別化医療とは、病気の性質や患者さんの体質に応じて、より高い効果とより少ない副作用が見込まれる治療を行うアプローチのこと。
例えば、同じ「胃がん」という病気であっても、遺伝子などによって複数のタイプに分類することができ、個別の状況に応じて最適な治療を行うことができるようになるわけです。
今回は、そんな個別化医療の深化に向けて研究と事業開発に取り組んでいる日立製作所のプロジェクトチームに、どのような流れで研究が進み、どのようなソリューションとしてビジネス化したのか、お話を伺いました。
目次
プロフィール

研究開発グループ デジタルサービス研究統括本部 先端AIイノベーションセンタ 知能ビジョン研究部 主任研究員

研究開発グループ デジタルサービス研究統括本部 先端AIイノベーションセンタ 知能ビジョン研究部 研究員

インダストリアルデジタルビジネスユニット エンタープライズソリューション事業部 医薬システム本部 第二システム部
ディープラーニングがもたらしたパラダイムシフトに合わせて医学系の研究を選択

――今回は再生医療領域のDXソリューションについて伺いたいのですが、その前に、柴原さんが博士号を2つお持ちだということに驚いています。具体的な研究内容の話に入る前に、どのような経緯で社会人大学院生として医療に携わることになったのか、教えてください。
柴原: 最初に修了した大学院では、3次元の空間情報を扱う画像認識技術として、コンピュータビジョンや自動運転における機械学習に関する研究をしていて、2008年に日立に入社してからも、画像認識分野の研究開発を続けていました。
そんな中、2012年9月に行われた画像認識コンペILSVRCにおいてカナダのトロント大学研究チームが圧倒的な予測精度を達成し、ディープラーニングが大きく注目されることになりました。また、その当時はビッグデータも話題になり、コンピュータビジョンや機械学習の分野でパラダイムシフトが起きはじめていました。大量のデータがあれば、実用が難しいと捉えられていた機械学習が実世界での活用に耐えうるものになると感じました。
パラダイムシフトに合わせて新しく研究を始めようとしたとき、医療とAIの組み合わせは良いのではないかと考えました。医学や薬学の分野に携わっている方々は、普段から統計を使っているのでしょうから、同様の数学的な背景を持つ機械学習とも相性がよいと思ったのです。
――そこから全くの新しいキャリアとして、日立にいながら大学院の医学部にも入学した、ということですね。
柴原: はい。医学分野について右も左も分からないような状態だったこともあり、医学部に入学して新しい研究をしながら学んでいこうと思いました。
入学後は、癌の治療戦略を立案することを目的として、薬を投与したときに発生する副作用の強さや発生のタイミングを解析する研究を始めました。最初は、機械学習を用いて予測精度を追求する方向で研究を考えていました。
しかし、医師である指導教官とディスカッションをすると、「どういう患者さんに副作用がおきやすいのか?」といった、予測精度よりも、予測結果の意図を問うような質問をたくさんいただきました。これはディープラーニングなどの機械学習が苦手とする領域で、精度の高い予測モデルを作るだけではダメなのだと、今にしてみれば当たり前のことに気付きました。
これが社会人大学院生として医学に関わることになり、この後にお話しする研究やソリューションのきっかけになった出来事でした。
――なるほど。その後はどのような流れで、研究やプロジェクトを進めていかれたのでしょうか?
柴原: 2016年からは日立としての共同研究をスタートさせ、AI・機械学習の説明性をメインテーマに研究を加速することにしました。
そこから研究を着々と進めていき、2017年に説明性を兼ね備えたディープラーニング技術が出来上がると、米ハーバード大学のメディカルスクールが所属する病院グループに協力していただいて、大規模なデータを使って実証を進めました。
それとほぼ同時期に、物理学研究を通して数学的な素養の深い山下さんがプロジェクトにジョインしました。
そして2018年には、ビジネス化に向けた取り組みが本格化し、根本さんが所属するビジネスサイドもプロジェクトチームに合流して、現在の「バイオマーカー探索サービス」を立ち上げました。
※バイオマーカー:治療に対する有効性・安全性を評価する生体内指標のこと。近年、個別化医療の実現に向け、バイオマーカーを探索する研究が盛んに行われている。
個別化医療の実現をサポートする「バイオマーカー探索サービス」

――バイオマーカー探索サービスとは、どのようなサービスなのでしょうか?
根本 : お客さまが持っているデータを日立に提供していただき、我々の方でAIを用いた分析を行って、例えば「このような条件を満たす人は薬が効きやすい傾向にあります」という結果(バイオマーカー候補)を提示するサービスです。データがあれば試すことができるので、基礎研究の段階から治験、そして薬が市販された後まで、様々なフェーズでお使いいただけるものになっています。
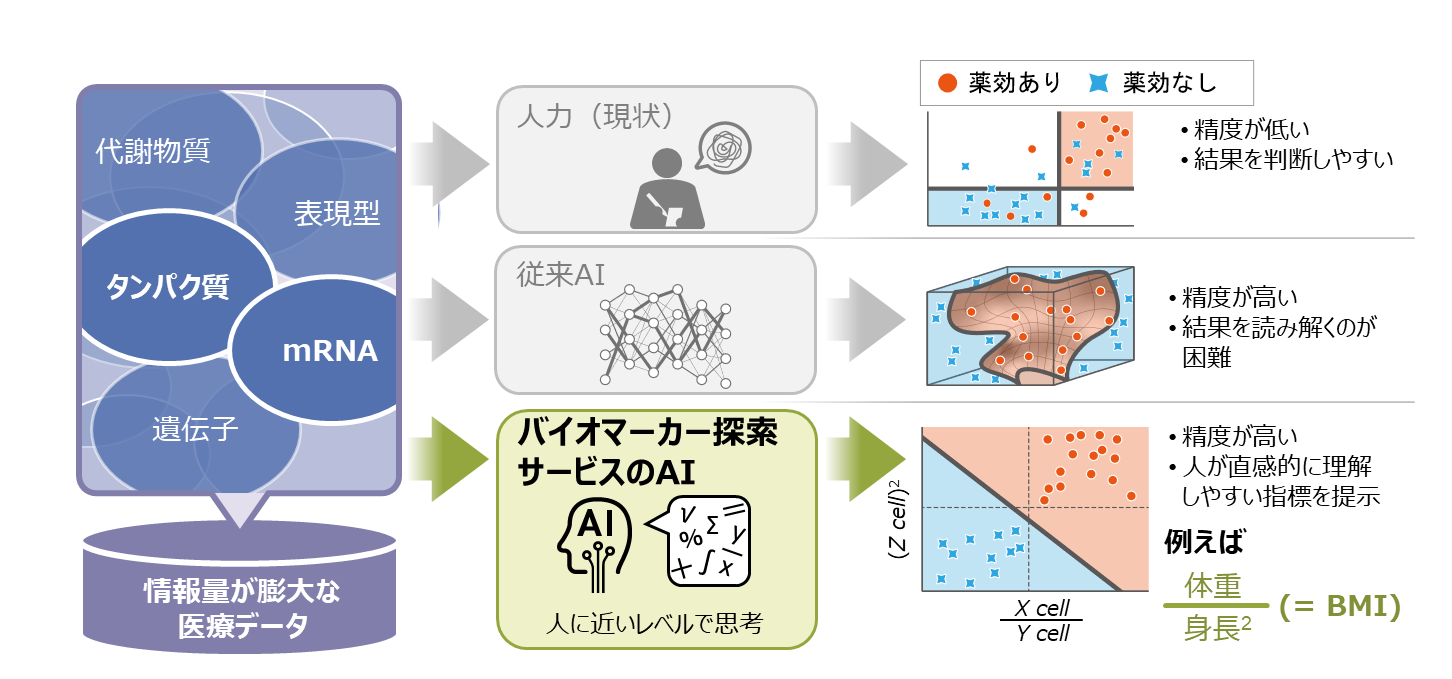
バイオマーカー探索サービスで使用するAIの特長。臨床研究や治験などの患者データから治療の有効性や副作用の予測に重要な因子を抽出した後,因子を用いて簡便な数式を組み立てることで,治療効果を高精度に予測可能な指標を自動生成する
根本 : 医療業界で大きなトレンドとなっている「個別化医療」の目的は、患者さん一人ひとりの体質や病気の状態に合わせた治療を提供することにあります。この個別最適化された医療のためには、高精度なバイオマーカーを早く見つける必要があるのですが、治療の有効性・安全性を高精度に予測するために遺伝子やタンパク質を組み合わせて探そうとすると、それこそ数千万〜数億というパターンになるので、人手では限界があります。
だからこそ、この領域のDXを進めるべく、研究成果であるAIを活用したサービスを提供しています。
――なるほど。詳細の研究内容はこのあと柴原さん・山下さんにお聞きするのですが、おふたりの研究成果をもって、まずはどのようなアプローチで事業化を進めていかれたのですか?
根本 : 使ってもらわないことにはAIの価値を分かってもらえないので、柴原さんや山下さんが作られたAI技術をご紹介しながら、製薬会社さまをはじめとするお客さまが持つ課題をヒアリングしていきました。
――製薬会社さまからは、具体的にどんな課題があがってくるものでしょうか?
根本 : 例えば、薬が効く・効かないの条件を見つける際に、既存の統計解析手法ではなかなか見つけられないテーマに対して、AIへの期待値が高まっているという状況でした。
現在は、複数の製薬会社さまに使っていただいていまして、「AIを使ったからこそ有効な条件を発見することができた」という声をよくいただきます。
とはいえ、人の身体に関わることで、一足飛びには進めることができないので、慎重な姿勢でプロジェクトを進めています。
――提供にあたっての課題はありますか?
根本 : 先ほどお伝えした通り、本サービスではデータを日立に提供していただいて、我々の方でAIによる解析を行って結果をお返ししているのですが、ここにまずハードルがあります。解析対象となるデータには個人情報が含まれているデータもあり、外に出すためにはマスク処理など、多くのプロセスを必要とします。特に、個人情報の中でも遺伝子レベルのデータになると、より一層慎重に検討をする必要がありますが、そういうデータがバイオマーカー探索の主流でもあるため、個別化医療を深めるために利用したいというお声も頂戴しています。
個人情報の保護と個別化医療の深化との兼ね合いを考えながら前進していかなければならないという、非常に難しい状況ではあります。
また、研究者の方を中心に、自分たちでも解析できるようにしたいというご要望もいただきます。現在は受託開発のような形で提供していますが、上記のようなハードルや要望を受けて、今後はWebサービス化などをしていくことも検討しています。
ロジスティック回帰モデルの「説明性」を使う

――先ほどおっしゃっていた「説明性のあるAI」を医療領域に適用するにあたって、具体的にどんな壁がありましたか?
柴原: そもそも医師や医学系の研究者がどういう説明を欲しているのか、医学研究における説明とはどういうことなのかを考えるところがスタート地点でした。
その結果、我々は「アウトカムを予測したときにどの因子が重要だったかを列挙できること」を「AIの素朴な説明」とみなしました。
AIの予測した結果とその意図を、医師が議論できるエビデンスをAIの説明として提供できれば良いなと考えたのです。
例えば薬効を予測した際に、「ある検査値が低い患者さんには効果が示されやすい。」といった具合に、予測結果に紐づいた因子を提供できれば、まずは第一歩かなと考えました。
それは、「ロジスティック回帰」という、最もシンプルな統計・機械学習が持つ説明性そのものです。
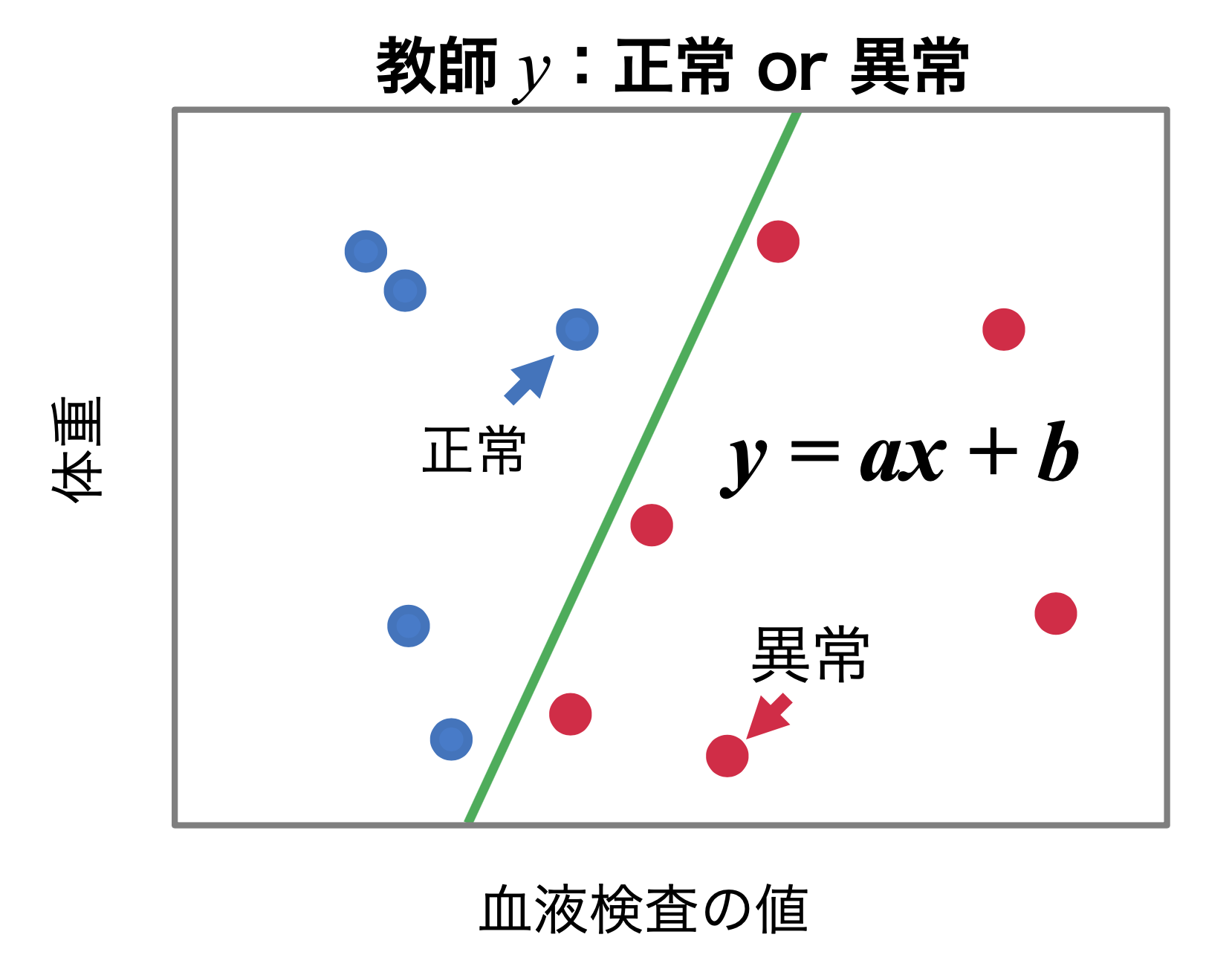
1958年にCox博士が考案したロジスティック回帰は確率値を出力する学習モデルです。予測された確率値を閾値処理することで、識別を行うことができます。
柴原: 例えば、「y = 0.1 × 赤血球の数 + 1.0 × 白血球の数」という回帰式があったとします。これを見ると、赤血球には0.1の係数が掛けられているのに対して、白血球は1.0の係数が掛けられています。白血球の方が赤血球に対して、大きな係数が与えられていることから、予測には白血球数が影響を与えていると考察することができます。
――なぜ、ロジスティック回帰という手法を選択されたのでしょうか?
柴原: ロジスティック回帰は1950年代にCox博士が提案し、現在でも最先端の医学研究で使われているモデルです。ロジスティック回帰では因子に紐づく回帰係数を用いて、個々の因子が持つ重要性を議論することができます。回帰係数ベースの説明性に落とし込んであげれば、医学分野の研究者もフォローできると考えました。既に知っていて、使い慣れているわけですから。
また、医学分野では対象が「人」です。臨床的な結果を議論する際の礎とする統計値の計算に、新しい技術を導入することに対しては保守的であろうとも思いました。そこで、Cox博士の作り上げたロジスティック回帰の肩に乗って、研究を進めることにしました。
もちろん、「機械学習という新しい予測モデル」を使ってくださる医師や医学研究者もいらっしゃいますが、医学論文の査読者までを考えると、なかなか難しいだろうなと。
――そこでロジスティック回帰をディープラーニングで計算してみましょう、という考え方で進めることになった、というわけですね。
柴原: そうですね。誤解を受けやすいので少し補足しますと、もともと識別を行う用途のディープラーニングの最終層にロジスティック回帰は入っているのですが、それのことではありません。回帰係数を予測するモデルをディープラーニングで組み上げています。いわゆるメタ機械学習ですね。
患者一人ひとりのためのモデルをオーダーメイドする

――ロジスティック回帰をディープラーニングで計算するとは、具体的にどういうことでしょうか?
山下 : ロジスティック回帰は、先ほど柴原さんがおっしゃったとおり、非常にシンプルな式のモデルになっています。[定数係数 × 変数の和]で薬が効くか効かないかを決めるモデルなので、分かりやすいというメリットがある反面、精度にはある程度の制限があります。
これに対してディープラーニングはもっと複雑怪奇な式を組むので、モデルの精度としては格段に向上します。しかし、そのままでは人間にはとても理解できないようなものになっているので、どの変数が効いているのかが分からない、説明ができないという問題が新たに発生します。
そこで、ディープラーニングを使って、ロジスティック回帰の“係数”を予測するようなモデルを構築しました。この回帰係数を算出する部分にのみ、ディープラーニングを使っています。当然ながら先ほどと同じく、回帰係数を算出したロジックの詳細自体は人間では理解が難しいのですが、少なくとも大きな係数が掛けられているのはどの変数かという意味で「重要な変数は何か」を理解することはできます。
柴原: 予測結果の算出とその説明のインターフェースとして、ロジスティック回帰を使っていただきます。その際、回帰係数は、Rなどの統計パッケージを使って計算されたものではなく、ディープラーニングをメタ機械学習として活用した日立の統計パッケージを使って計算されたもの、ということです。

ロジスティック回帰と同様に回帰係数で結果を議論することができる
――なるほど。あくまでユーザーとしては、同じロジスティクス回帰という使い慣れた道具なので、特に気になるところではないということですね。
柴原: 知っているものから、理解を深めていただけると良いなと願っています。通常のロジスティック回帰と異なるポイントは、それぞれの患者さんにとって「オーダーメイド」となるロジスティック回帰モデルを作ることができるという点にあります。
先ほど根本さんがおっしゃったとおり、医療の世界では個別化医療の流れがきており、個々人に最適化されたロジスティック回帰モデルは、この大きな流れと親和性が高いものになると思いました。
従来の「なるべく多くの人に効く薬」から「効く人にはすごく効く薬」へとパラダイムシフトが起こる中で、効く部分の特定の仕方を、我々が支援するということです。
――途中からジョインされた山下さんは、この方針の中で、具体的にどのような役割を担われたのでしょうか?
山下 : 私は、どの因子が重要かという、XAI(説明性のあるAI)における重要度スコアの決め方をメインで担当しました。
今、柴原さんから、個々人に最適化されたロジスティック回帰モデルとお伝えしましたが、これを逆に捉えると、統計的に何が効いているのかをどういう風に決めるべきか、という問題がまだ残っていることになります。
――一人ひとりの説明はできるが、今度は全体的な傾向の説明ができない、ということですか。そもそもなのですが、全体の傾向はなぜ必要なのでしょうか?
柴原: 個々人に効くことの次は、薬が効く集団という「サブグループ」を見つけたいということかなと思います。個々人に最適化された薬を作ってその人だけに提供できれば良いのですが、道のりは長いです。当面は「1,000人いたら、その中の1人ではなく100人ほど」のような、その中間が必要になり、それを自動で見つけるとなると、その間をつなぐ技術がまた必要になるわけです。
こちらは、国立がん研究センターの先生方と共同で研究を進めています。
見つかったバイオマーカーは説明可能なものだった

――国立がん研究センターさまとの研究内容についても教えてください。
柴原: 共同研究を行うことになった背景からお話しますね。例えば、ある病気を患っている患者さんのうち、半分の患者さんにはとても効果を示す薬があったとします。しかし、投与前に効く患者さんを特定できないとすると、その病気に対する薬の効果を集団的に見れば半減してしまいます。
特定の患者さんにしか効果を示さない薬や治療は、その患者さんを事前に特定できないと活用するのが難しい状況になります。そこで、何かしらの検査値、バイオマーカーと呼びますが、薬が効果を示す患者を特定するためのバイオマーカーを探索する研究に参加させていただけることになりました。
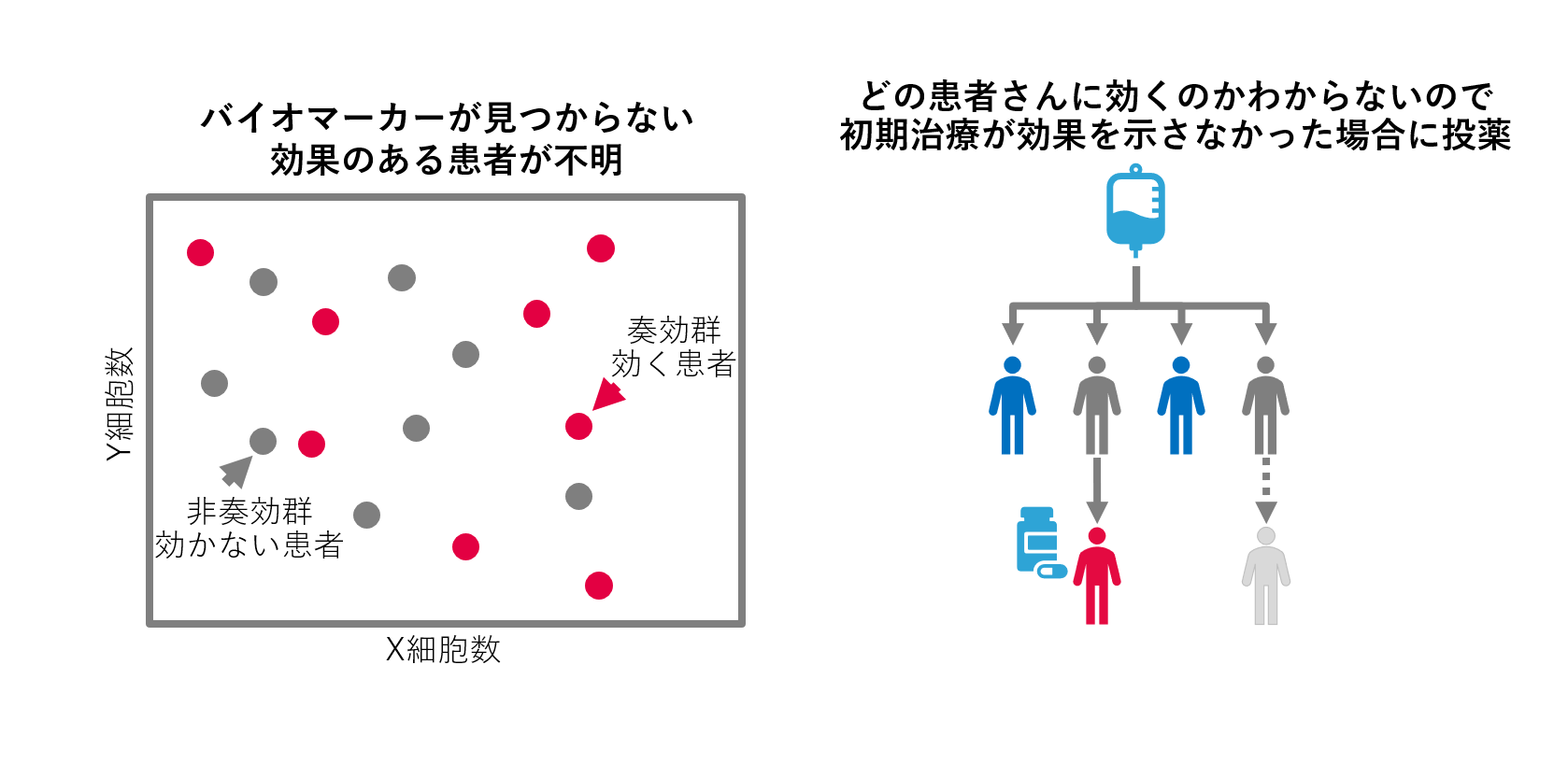
柴原: 以下の図のように、2つの因子を見つけて患者さんを特定できたら良いですよね。私たちの研究では、ある新しい薬に対して、このようなバイオマーカーを見つけたかったのです。そうしたら、効きそうな患者さんには治療の1つの選択肢になりますし、そうではない患者さんには別の治療方法を最初から検討できるようになります。
個別医療の実現は患者さん、医師、医薬品の研究者、私達の願いです。また、医療費の削減にも繋がります。
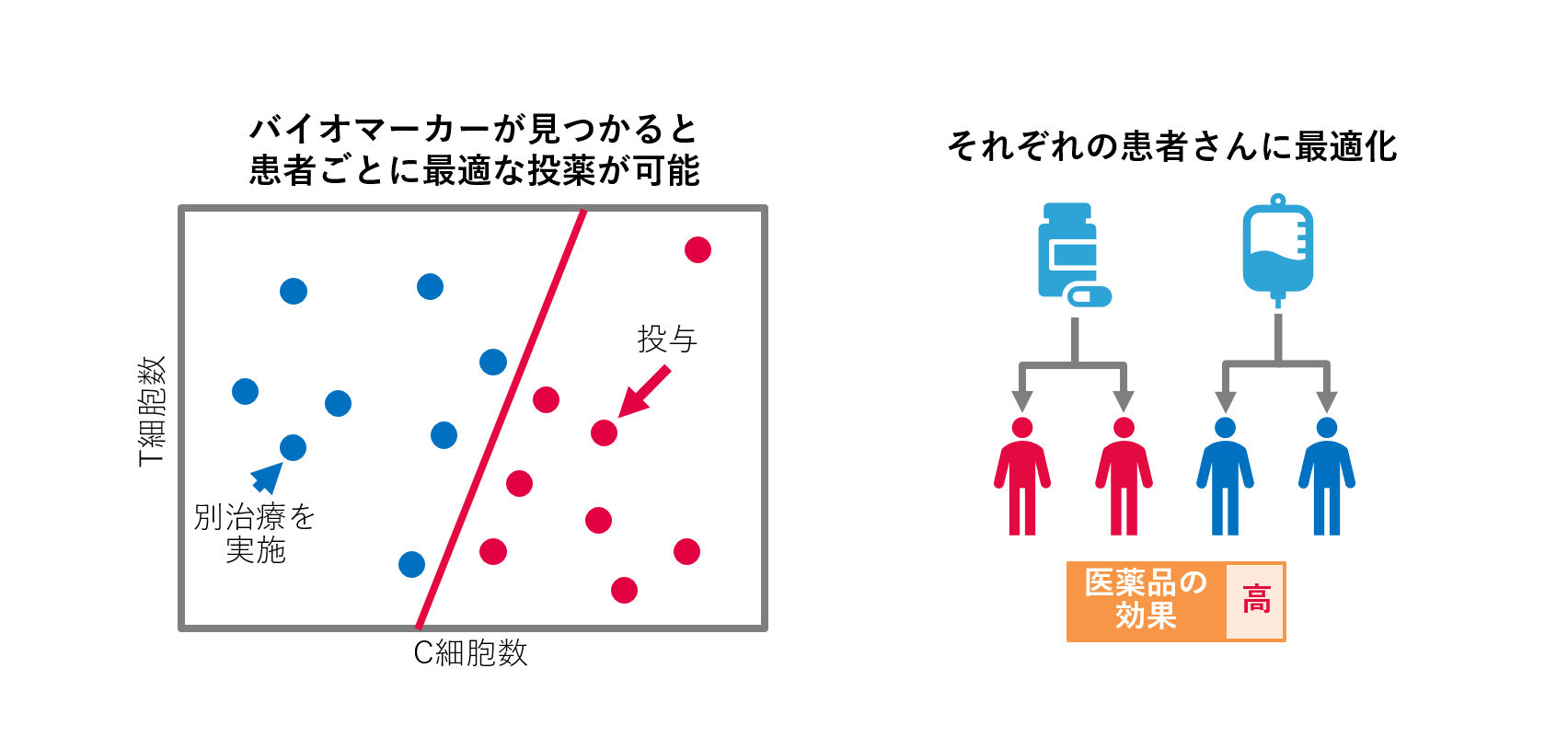
柴原: 実際に、ある抗がん剤に対してバイオマーカーが無事に見つかりました。
――さらっとおっしゃいましたが、すごいですね!見つけたバイオマーカーからどのように「薬が効くか否か」を判断したのでしょうか。
柴原: がん細胞があると、その周辺に免疫細胞が集まってくるのですが、その免疫細胞に関して取得した数百種類の情報・因子を取得します。そして、薬効を予測可能な因子をバイオマーカーとして探索する際に、我々の機械学習技術を導入していただきました。最終的には、免疫を促進する細胞と抑制する細胞に関する因子が特定され、促進と抑制のバランスとして薬が効果を示すかそうでないかを説明できうるとの結論でした。ぜひ、プレスリリースや論文をご覧ください。
※詳細の共同研究成果についてはこちらの国立がん研究センターのプレスリリースをご参照ください
今度は「数式を作り出すAI」にチャレンジ

――本研究やソリューション開発の未来像について、今後目ざしていることを教えてください。
根本 : お客さまとお話をする中で、かなりニーズが細分化されていると感じています。その中でも多いのが、数十例といった少ない症例数でも解析できないかという要望です。これは、創薬ターゲットがかなり細分化された疾患領域や希少疾患など、患者が限られる アンメット・メディカル・ニーズ領域にシフトしていることとも関係すると考えています。従来よりも少ない症例で解析できる技術が求められており、ソリューションとしてもしっかりと対応していきたいと思います。
山下 : 今根本さんがおっしゃったことを実現するための取り組みは、現在進行中です。先ほど2つの白血球のお話がありましたが、実際には[攻撃する白血球の数 – 抑制する白血球の数]のような数式を見つけた形です。このような式そのものを機械学習で見つけてくる、ということをやりたいと思っています。
今お伝えしたケースでは引き算の式ということでとてもシンプルなのですが、掛け算や割り算、三角関数や指数対数関数などを用いたもっと複雑な数式を弾き出すAIに向けて研究開発を進めています。
――数式そのものを算出できると、どんな良いことがあるのでしょうか?
山下 : そもそもディープラーニングにデータ数が必要なのは、ものすごく大量のパラメータの入ったモデルになっているからです。十分なデータ量があれば良いモデルが手に入るのですが、少ないデータだとその少ないデータにしか当てはまらない過学習モデルができてしまいます。
ですが、我々が考える「数式を作り出すAI」であれば、パラメーターの数がとても少なくてすむ可能性があります。たとえばexp(x)(exponential x:xの指数関数)の数式が欲しいとき、ディープラーニングだと1 + x + x²/2 + x³/6+・・・のような各係数を決めなければならないのですが、「数式を作り出すAI」の場合は「exp(x)」の一言で言えるので、たくさんのパラメータを決める必要がない、つまり過学習のリスクが低減されます。また、モデルの形が式として得られるので分かりやすいというメリットもあるので、XAIとしてもとても良い方針だと考えています。
――「式を算出する」ということのイメージがいまいちできていないのですが、これは、大量に式が出てくるということですか?
柴原: そうですね。意外性に富む式が出現します。それらの式の中で予測精度の良いものから順に、どのような仕組みで予測しているかをレビューします。統計的な信頼性だけではなく、人が蓄積してきた知識も使ってバリデーションを行なって、さらにリーズナブルな式を探させます。
人間とAIのコラボレーションで進めていくイメージですね。

柴原: 一番右にあるように「BMI = 体重 / 身長²」という式で出されたら、分かりやすいですよね。式で出せるものだったら、ぜひ式を算出して活かしましょうというのが、我々のスタンスです。
柴原: いわゆる強化学習ですね。囲碁AIなどで目覚ましい成果が記録されている領域です。我々の場合は「数式を打つ」ということで、強化学習を使って科学者と同じようにバイオマーカーとなり得る因子と数式の組み合わせを探索していくことも、研究テーマに据えています。
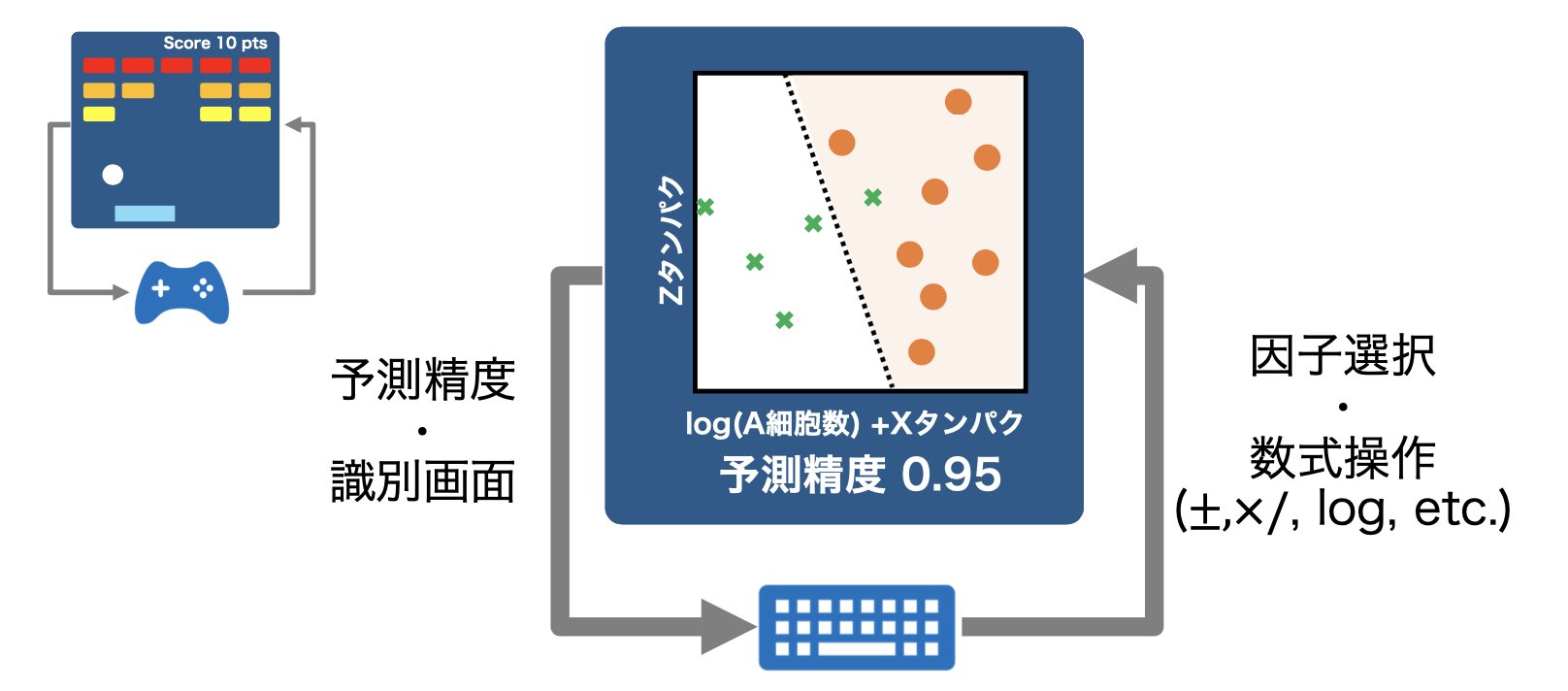
線形モデルで識別された画面を見て、 予測精度が向上するように操作する
柴原: 先ほどお伝えした「コラボレーション」を通じて、ぜひお客さまからのフィードバックループがぐるぐると回るような、そんな世界を目ざしたいと考えています。実験室の世界と、計算機上の世界を一緒に回していくということです。
こういう領域は、やっておしまい、予測しておしまい、ということが往々にしてありますが、根本さん等ビジネスサイドと連携して、しっかりとループを回していきたいと思っています。
日立にいると、時々本当にすごい人とエンカウントする

――本日のお話は非常に面白い取り組みだと感じます。このような研究や事業化を「日立」という環境で進めることを、どのように感じられていますか?
根本 : 社内には様々な専門知識をもった人がいるというのが大きいと思います。何か新しいことをやろうと思ったときに、その分野に詳しいエキスパートがいて、その人とタッグを組みながら考えていけるのは大きいと感じます。
あとは、新しいビジネスをやろうとする土壌があるのもいいと思います。ハードルが高いことであっても、組織としてチャレンジできる文化になっているのはありがたいですね。
――根本さんは、データサイエンティストとして顧客からのデータ解析の役割も、一フロントとして課題を拾い上げる役割も担っていると思います。ロールが広いと感じるのですが、今後のご自身のキャリアとしては、どう考えられていますか?
根本 : しばらくは今と同じようなポジションかなと思っています。研究者が作った技術を活かして様々なデータを解析できることに加え、お客さまと会話する中で業務における課題や業界動向を知ることもできるので、おいしいポジションかなと考えています。
――いいですね!山下さん・柴原さんは、日立という環境をどのように感じていますか?
山下 : 私の所属する研究開発グループにはデザインを専門としている部門があり、その中には社会システムやサービスなどをデザインしているチームがあります。バイオマーカー探索サービスについても、私たち研究者と根本さんのチームの間に入って技術の難しい部分を関係者全員で理解してサービスを検討できるようにするための合意形成や、複雑な技術やそのシステムを簡明に表す手法をデザインしてくださるデザイン部門のメンバーがいました。大学にいた頃はそういったデザインを専門にしている方と一緒に働く機会をもつことは難しかったので、社会に提供する際にデザインを専門に扱うプロフェッショナルがいるのは非常に心強いと感じます。
▼日立のデザインシンカーについて詳細はこちら
https://zine.qiita.com/interview/202105-hitachi-3/

柴原: 日立で研究をしていると、驚くほど優れた研究者、過去には物理学者の外村彰さんがいらっしゃいましたが、また、研究のビジネス化を達成している研究者もいて、示唆に富む意見やアドバイスをいただけるので、ありがたいなと思うことがあります。
あと、これは日立のような歴史のある企業だからこその視点なのですが、何年も積み重ねて組織の価値を形成し、その歴史が培ってきた社会的な信用をもって人と話せるという点もありがたいです。何か新しいことをお客さまに提案する時に、私個人では門前払いになってしまうかもしれないことでも、「日立さんの中央研究所の研究者」ということで、話を聞いてもらうハードルがぐっと低くなります。忘れがちですが、これはすごいことだと思います。
――素晴らしいですね。個人としての目標はいかがでしょうか?
山下 : 今後のキャリアについては、機械学習をもっと理解したいなと思っています。今私が携わっているXAIですが、先ほどお話した重要度スコアは1つの側面の理解でしかないため、より多様な側面から理解すべきだと感じています。
柴原: 機械学習というパラダイムがどこまで続くかは分かりませんし、新しいフィールドを見つけたいです。
日立では、会社の資産を使って事業をスタートアップできる

――最後に、読者の皆さまに一言ずつメッセージをお願いします!
山下 : 私にとって研究は、ある程度自分の好きなことをして、楽しく仕事をして生きていくための方法の1つです。専門トピックについて深く考えて追求でき、その他の専門家の仲間がいて議論して理解を深めて、新しい発見をする。そんな新しく素晴らしい働きはいかがですか、とお伝えしたいです。
根本 : よく就職活動をしている学生の方から「希望ではない配属先になりますか?」と聞かれます。もちろん企業なので100%希望の配属先に行けるわけではありませんが、グループ公募などの制度があり、手を挙げればやりたいことができる環境は充実していると感じます。毎週数件の公募がオープンになっており、実はうちのチームも現在(2022年4月下旬時点)公募中なので、配属先に関わらず、チャンスは多いと思います。
柴原: 研究者としてとても大きいと感じるのは、研究の不安定さは取り除けないので、少なくとも生活の方が安定するのは良いことだと思います。仕事として研究を進めつつ、新しい研究を探すこともできます。現代の研究者にとっては、貴重な職だと思います。
あと、何かしらのビジネスをやりたい方にとっては、企業の資産を使ってスタートできるのは良いかも知れません。我々も何もないところから研究をスタートさせ、多くの方々の手助けを受けて、ビジネスにまで引っ張り上げられています。そういう土壌があるので、事業思考の強い方には良い環境かも知れません。
※バイオマーカー探索サービスを含む医薬品・医療機器業界向けDXソリューション (Hitachi Digital Solution for Pharma)の紹介動画
編集後記
今回のお話は、日立製作所の研究者ライフの魅力を垣間見ることができる、非常に刺激的なインタビューでした。会社の制度として社会人大学院への通学が認められること、教授との共同研究を通じて技術を突き詰めていき事業化までもっていけること、そして事業化に向けて最高の専門家がチームへとジョインしていること。最後に柴原様がおっしゃったとおり、安定した生活基盤があるなかでこのような研究開発環境に没入できるのは、非常に魅力的な研究者ライフだと感じます。ものごとの理を突き詰めたい研究者思考の方にとっては、まさに素晴らしいフィールドとなるでしょう。
なお、東京・国分寺市にある日立製作所中央研究所の正門先には、冒頭と最後の写真にあるような「返仁橋(へんじんばし)」、またの名を「変人橋」がかかっています。まさに「凡人、才子にあらず変人たれ!」との思想から、そのように命名されたとのことです。今回のようなお話を、返仁橋がある中央研究所で伺えたことも、また素晴らしき機会だったと感じます。
取材/文:長岡武司
撮影:平舘平
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
日立製作所の最新技術情報や取り組み事例などを紹介しています
コラボレーションサイトへ
日立製作所の人とキャリアに関するコンテンツを発信中!
デジタルで社会の課題を解決する日立製作所の人とキャリアを知ることができます
Hitachi’s Digital Careersはこちら