コードの類似性に着目し、独自のアルゴリズムでバグの種を潰す!Sider ScanをQiitaに携わるエンジニアが試してみた

システム開発を進める上で、バグとのお付き合いは不可避です。バグは必ず発生するものですが、コードレビューや静的解析ツール等を導入するなどして、バグが発生しにくくなるような環境を構築することは可能です。これは、大規模・大人数のプロジェクトでは特に重要になってきます。
今回は、そのような大規模プロジェクトにおいて、コード品質低下の主たる要因の1つと言われる「重複コード」、いわゆるコピペコードに着目し、独自のアルゴリズムを用いた静的解析ツール「Sider Scan(読み方:サイダー・スキャン)」を、Qiitaの開発マネージャーである大東 祐太が実際に使ってみました。
具体的にどのような指摘が入ったのか?使い勝手はどうだったのか?他のテストツールとの使い分けはどうするべきなのか?同ツールの開発会社である株式会社Sider CEOの浅原 明広さんとの対談を通じて、Sider Scanの活用ポイントを探っていきます。
目次
プロフィール

CEO

プロダクト開発グループ マネージャー
既存のLinterやテストツールとは異なる視点でコードレビューを行うSider Scan

大東 : まずはじめに、Sider Scanについて製品の特徴も含めて概要を教えてください。
浅原 : 端的にお伝えすると、人によるレビューとはまた違った観点でコードを分析してくれるAIコードレビューツールになります。
日々開発する上で、ソースコードはどんどん増えていくと思うのですが、コードが更新される度にSider Scanがコードをくまなくチェックして、バグやバグではないが書き換えた方が良いようなコードを見つけて、メール等で通知してくれるというものです。いわば、疲れをしらないタフなレビュワーを1人雇うようなイメージですね。
大東 : ソースコードの静的解析ツールは世の中にたくさんあると思うのですが、それらのツールとSiIder Scanにはどのような違いがあるのでしょうか?
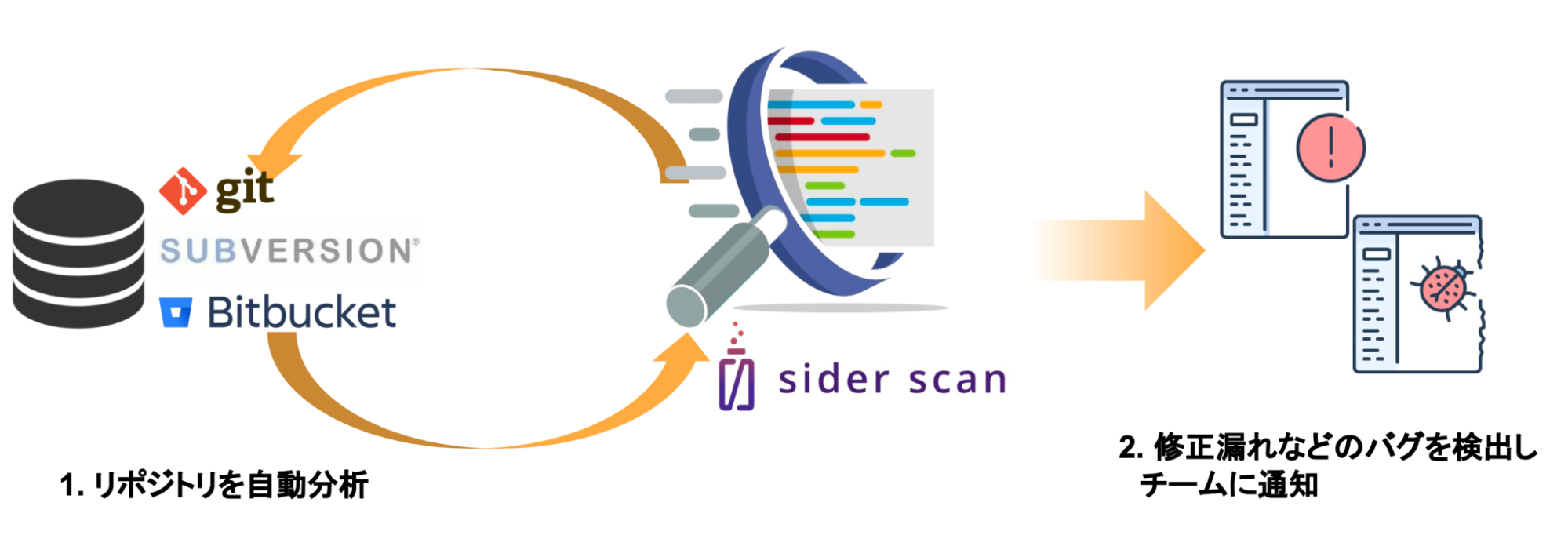
浅原 : 世の中にあるソースコードの静的解析ツールは、大きく2つに分けられると思います。
1つは、「Linter(リンター)」と呼ばれるもので、コードの書き方やスタイルをチェックしてくれます。様々な言語やオープンソースに対応した数えきれないほどのLinterがあるのですが、基本的にはルールの一覧が定義されていて、それに違反したものがないかの単純なチェックをするものになります。プロジェクト全体を分析することでわかるような複雑な問題などは検出されませんが、処理が軽いため、エディタのプラグインとしてリアルタイムに活用している方も多いでしょう。
もう1つは、「テストツール」と呼ばれるものです。こちらはLinterよりも複雑な分析ロジックをもっていて、前後の文脈も見てバグかどうかまでチェック・指摘してくれるようなものまでありますが、多機能なゆえに設定が複雑であったり、一度の分析にかなりの時間がかかるものが多いです。毎日使うものというよりも、製品のリリースや統合テストのタイミングなどで使うものですね。
Sider Scanは、処理速度としてはLinter に近く、高速です。流石にリアルタイム処理は難しいですが、CD/CIに組み込んで毎日使っていただくには問題ない処理速度を実現しています。
大東 : 確かに処理は速いですね。僕が使ったときも「こんなに早く終わるの?」と思いました。
浅原 : 今のはユースケースとしての特徴なのですが、Sider Scanが見つけるバグについてもユニークな特徴があります。
そもそもバグと一言で言っても、単純なタイポから文法ミス、仕様との不一致など、幅広い種類があります。その中で、既存のLinter やテストツールでカバーできるバグの種類はそれほど多くありません。現状では、ツールで拾えないバグは、人によるコードレビューや、人が設計したテスト工程でなんとか潰しているという状況でしょう。
Sider Scan が行っているのは、「プログラム中にある似たようなソースコードを比較しておかしな部分を見つける」ということで、一種の異常検知になります。具体的には、コピペ等に起因する「重複コード(コードクローン)」を高速で検出して重複ペア間の記述パターンを分析し、その記述パターンから逸脱したものを変更漏れ等のバグとして検知するというものです。Sider Scan も、様々なバグのうち、重複コードに起因する一部のバグだけを拾うツールになりますが、そのバグは既存のツールや人間のコードレビューでは検出しにくいものであるため、価値があると考えています。

著名オープンソースをSider Scan で分析することで見つかった変更漏れバグの例。cdev_count をz_count に変更するのを忘れている。このバグはプロジェクトに報告され、実際にマージされている(Intel Thermal Daemon: https://github.com/intel/thermal_daemon/issues/311)
浅原 : また、東京大学の千葉研究室や慶應義塾大学の高田研究室、南山大学の名倉研究室、大阪大学の肥後研究室など、複数のアカデミアと共同研究をしているのですが、このような最先端の研究者と議論しながらプロダクト開発しているという点も特徴の1つです。
重複コードに起因したバグを無くしたい
大東 : そもそもですが、Sider Scanを作ったきっかけは何だったのでしょうか?
浅原 : 私が経験してきたプロジェクトにおいて、今お伝えしたような、重複コードに起因するバグで痛い目にあったためです。実際、重複コードを人間がくまなく調べて管理するには限界があります。
例えばAさんがコピペをして重複コードを作ってしまったとします。Aさんの退職後にBさんが重複コードの片方を修正した場合、本来BさんはAさんがコピペをしたコードも含めて編集する必要があります。しかし、引き継ぎが不十分であれば、Bさんはコピペコードの存在を知りません。結果として、その修正によって別の箇所で不具合が発生する可能性があります。
このプロジェクトでは、そもそも「重複に起因したバグ」ということを誰一人認識できずに修正を繰り返すことになります。根本的には1つの原因に対して、もぐらたたきのような状況になり、修正が長期化するリスクがあるということです。
このような重複コードに起因したバグを無くしたいというのが、Sider Scanを作った最大の目的になります。
大東 : どのようなプロジェクトがSider Scanを使うのに適しているのでしょうか?
浅原 : Sider Scan に向いているプロジェクトには3つの特徴があります。
まずは、1年以上続いているプロジェクトですね。開発年月が長いプロジェクトでは、どうしても重複コードが増えていく傾向があります。
また、開発者の数が5人以上のプロジェクトについても、重複コードを作ったメンバーと、その重複コードを修正するメンバーが異なるケースが多いので、修正漏れに起因するバグが発生しやすくなります。
大東 : 1人や2人だと、自分でコピペしたかどうかが分かるので、修正漏れも発生しにくい、ということですよね。
浅原 : そうですね。少人数のプロジェクトであれば、個人の記憶でなんとかなることもあると思います。しかし、5人、10人になってくると、もはや記憶に頼るのは無理ですね。
最後の1つは、スキルセットの異なるメンバーが集まるようなプロジェクトです。新人の方やオフショア開発メンバー、外注などプロパー以外のメンバーが参画するようなプロジェクトでは、コピペや重複コードも発生しやすいので、こちらも注意が必要だと言えます。
まとめますと、開発期間が長く、開発メンバーの数が多くてスキルセットにバラツキがある大規模プロジェクトでは、Sider Scanは特に大きな成果を上げてくれます。
Sider Scanを製品化する前に、実際に様々な企業の様々なリポジトリで検証したのですが、その経験からも小規模プロジェクトよりも大規模プロジェクトで効果を発揮しやすいと感じています。
CI/CDに慣れ親しんだ人なら簡単に導入できる

浅原 : 実際に大東さんが使ってみた感想もお聞きしたいです。
大東 : とてもシンプルな表現ですが、すごく使いやすかったです。
QiitaはCIツールとしてGitHub Actionsを使っているのですが、まずはそこに組み込む前にローカルでDockerイメージを使って実行しました。それ自体はコンフィグを用意してコマンドを1つたたけば実行できるというくらい手軽に試せました。
またCIに組み込む際にも、使っているCIサービスごとにコンフィグのサンプルが用意されているので、そのテンプレートに従って設定ファイルを書くことで簡単に導入できました。
浅原 : 極力、導入自体は手順書を読めば誰でも簡単にできるようにしています。
あとは、CIサーバーの負荷を下げるとか、解析結果を共有する際のIP制限とか、解析結果の保存期間を変更するとか、細かい設定が可能なのですが、この辺りはSider Scan というようりもCIツールの話になります。「詳細はGitHubさんに聞いて!」と言いたいところではありますが(笑)、できる限り弊社でもサポートするようにしています。
Sider Scan自体の機能としては、CIツールにキックしてもらうか、単にコマンドを打ってもらうかで起動し、分析結果をどこかに出力するというシンプルなものです。出力先はGitHub ActionsやJenkinsのアーティファクトかもしれませんし、Amazon S3上かもしれません。ユーザーさまからは、出力先の設定の相談を受けることが多いですね。各種ドキュメントは用意していますし、チャットによるサポートも利用可能です。
大東 : あと、実際に動かした時の所要時間ですが、10分くらいで完了しました。最初にメールで質問した時は1〜2時間ほどかかるかもしれないとの回答があったのですが、実際にやってみたら相当短く済んだので、早い!と思いました。
浅原 : 具体的な時間は、解析ディレクトリのサイズや、重複コードの検知数によって大きく異なります。目安として、2000ファイル程度のリポジトリの初回の解析で30分程度かかります。2回目以降の解析は、前回の解析から変更のあったファイルのみ解析します。
先日リリースした最新バージョン(2.23)では、膨大な類似コードを含むような特殊なソースコードについて、解析を途中で打ち切る仕様にしました。これにより、解析時間を大幅に短縮できています。これまでの検証結果から、膨大な類似コードを含むコードは他のツール等で自動生成されたものある場合が多く、そのようなコードへの指摘は有益ではないことがわかっています。
Qiita環境で実行したら12個の指摘が入った
浅原 : 実際に動かした結果としてはいかがでしたか?
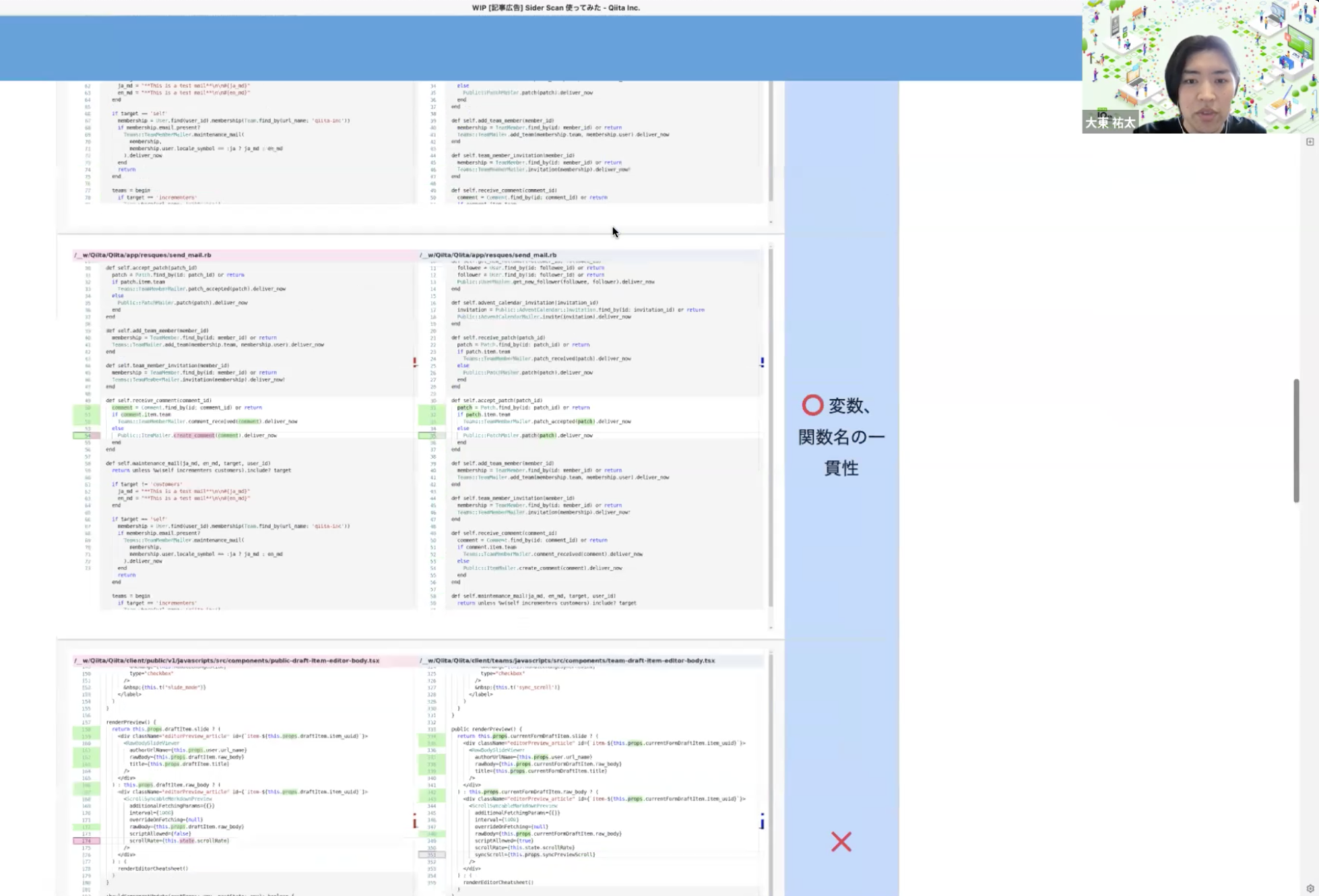
大東 : 数えてみたら12個の指摘が入りました。バグ検出はなされなかったのですが、変数や関数名の一貫性の欠如や、重複コードの検出がなされました。いずれもバグの温床になり得て、既存の静的解析ツールでは検出できないものだと思います。コードの品質向上に貢献してくれました。
僕らもエンジニア間でレビューをしているのですが、先ほど浅原さんもおっしゃっていた通り、重複の存在をそもそも知らないと指摘もできないので、人間だけでは発見が難しいものを簡単に見つけることができる点も良いなと思います。
浅原 : Qiitaさんもプロダクトの歴史が長いですからね。
大東 : 2021年秋に10周年を迎えたのですが、10年間ずっと同じメンバーで開発しているわけではありませんし、当然ながら知らないコードも出てきます。開発規模としても15名体制でやっているので、まさにSider Scanのターゲットになりますね。
また、解析結果はメールで届くと思うのですが、この設定も楽でした。よくあるクラウドサービスだと、大体Slack連携の設定などをする必要があると思うのですが、Sider Scanの場合は設定ファイルにメールアドレスを書いておけば、それだけで解析結果がメールで届くので、試すためのハードルを最小限にしていると感じます。
浅原 : 私たちは、メーリングリストをダッシュボード的に使っていますよ。
大東 : ダッシュボードって、どんなイメージですか?
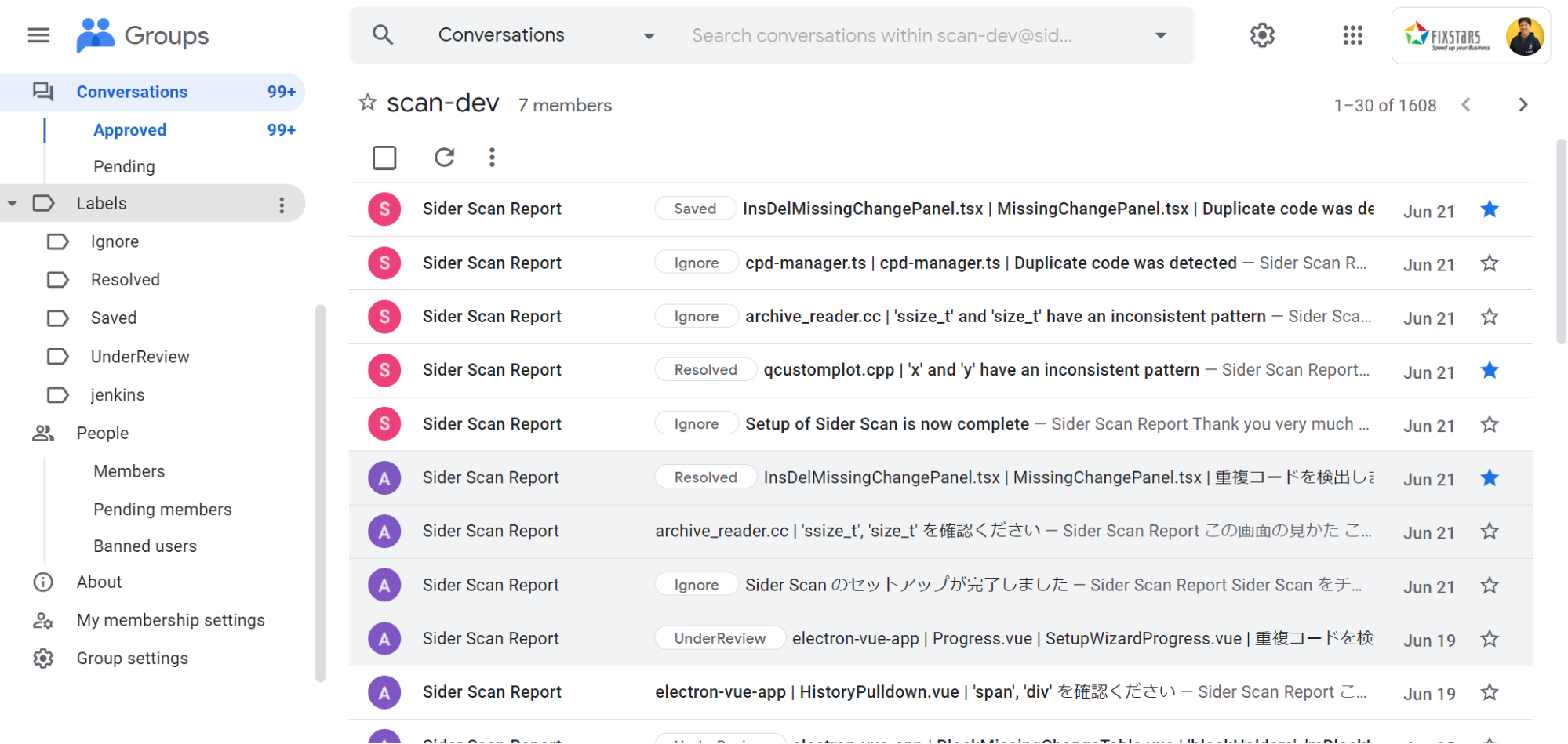
浅原 : これがうちで使っているメーリス画面です。Google グループを使っています。これで通知をみんなで見ることができて、その中の1つを開いて「CIサーバーで詳細を見る」ボタンを押すと、そのまま詳細の解析結果を見ることができます。
大東 : これだと分かりやすいですね!
浅原 : 我々自身がダッシュボードを提供しようとすると、それだけでかなりの工数がかかってしまうので、ここはメールが持つ機能に乗っかってしまおうというアイディアです。
例えば、Google グループでは、指摘のメールの一つひとつに、スターをつけたり、ラベルをつけたり、あるいはゴミ箱に捨てるなどして管理することが可能です。
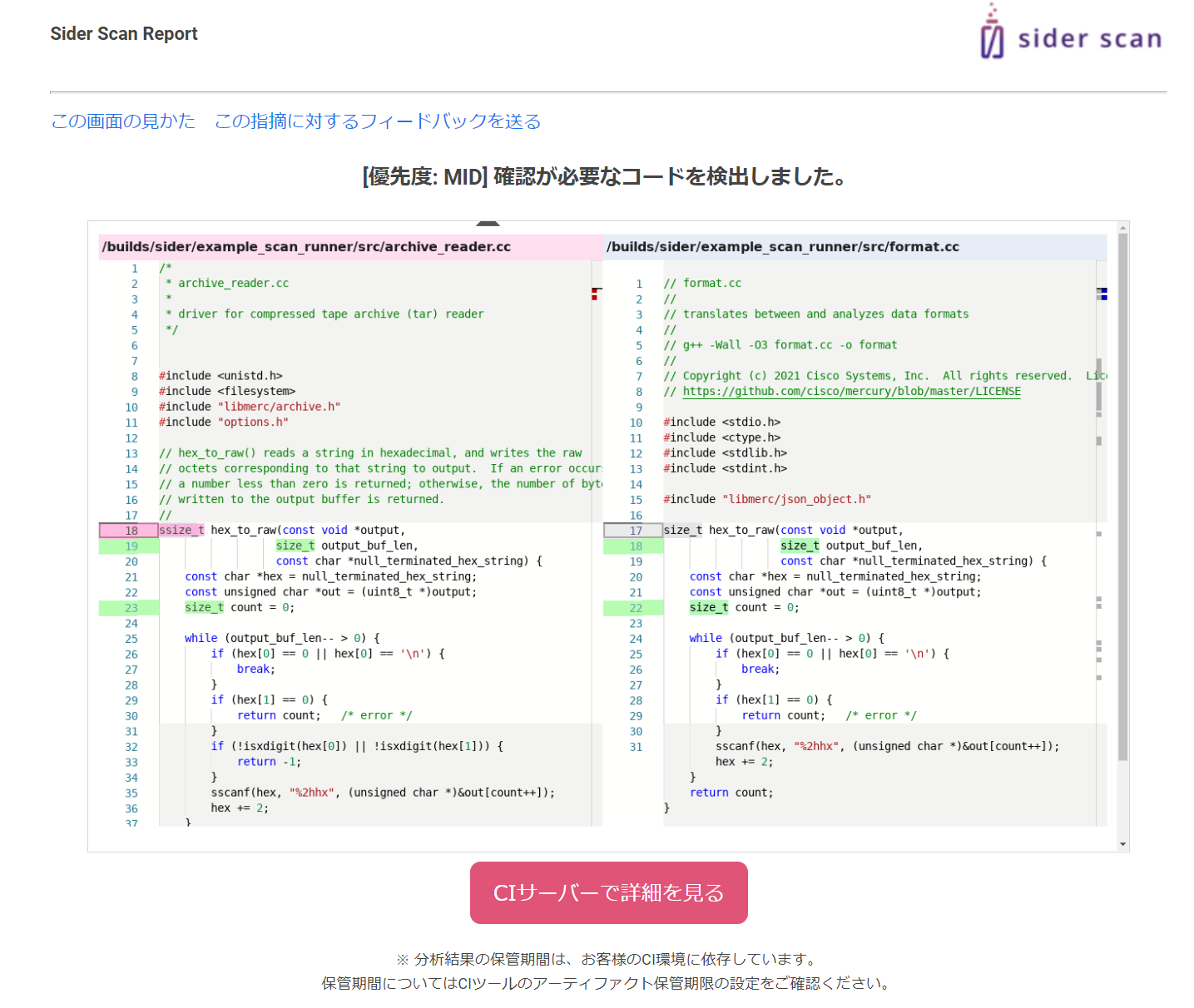
ちなみに、確認していただきたいコードは、「要確認コード」として1件ずつ分かれたメールとなっています。それぞれの「要確認コード」には確認すべき優先度がHIGH, MID, LOW で重み付けされています。是非、HIGHのものから順に確認してください。
インテル社Thermal DaemonやApache Kafkaなど、著名なオープンソースコードで次々とバグを検出
大東 : 実際のバグ検出事例も教えていただきたいです。
浅原 : ユーザーさまの事例はご紹介できないのですが、著名なオープンソースコードを勝手に分析して、勝手にバグを治すという活動をしています。これまで50以上のオープンソースプロジェクトでバグを見つけ、そのうちの一部は、実際にプルリクやイシューを提出し、マージされています。
大東 : メンテナー的にもありがたいですね。
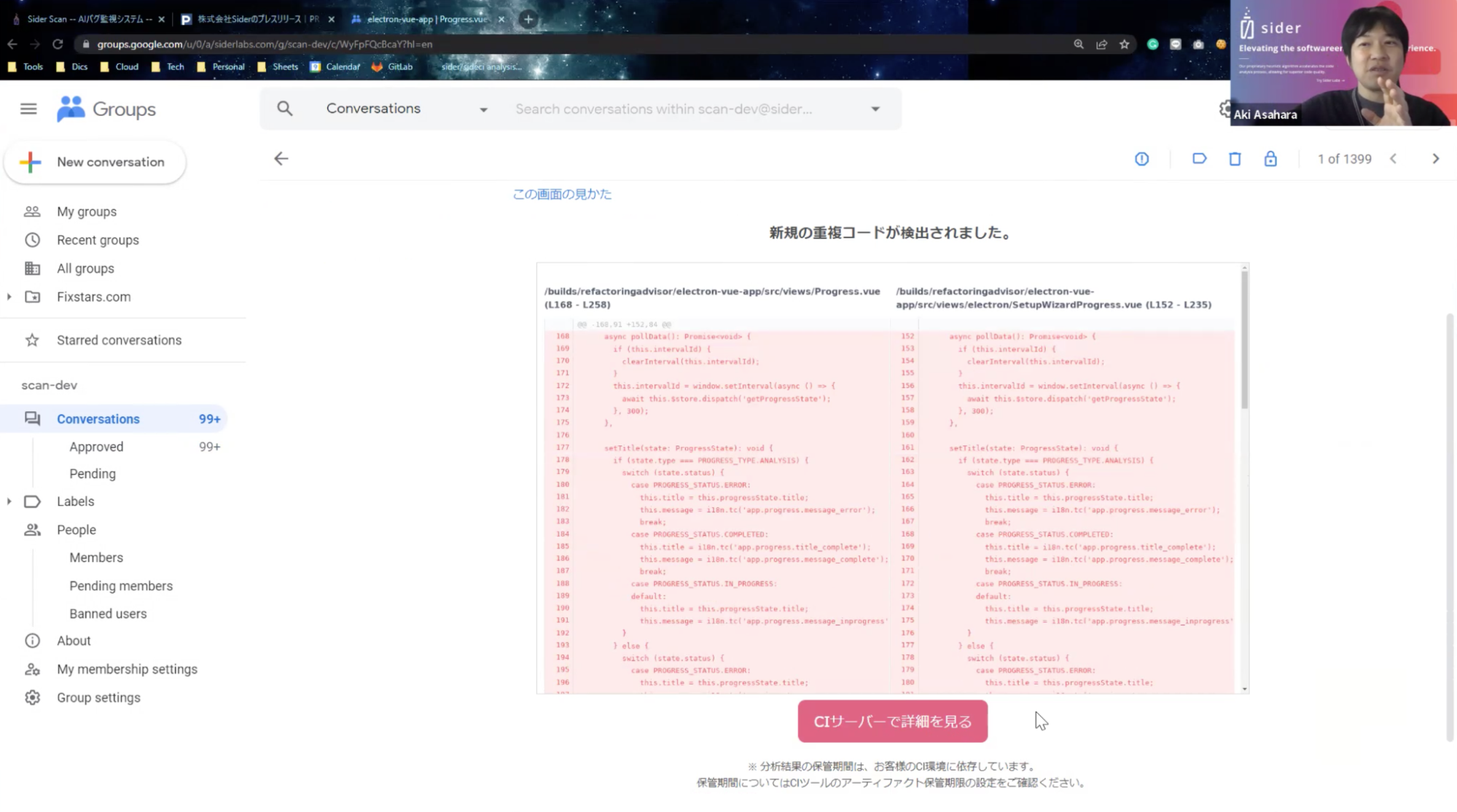
浅原 : 有名なところですと、例えばインテル社のThermal Daemonと呼ばれる、Laptop用のCPU温度管理ツールのコードが挙げられます。

浅原 : 右側では”cdev_count”に対する処理を、左では同じロジックで”z_count”に対する処理をそれぞれ行っているのですが、ここで110行目にある”cdev_count”が修正漏れなのではないかと指摘しました。こちらはメンテナーに連絡をしてバグを確認してもらい、プルリクエストを送り、レビューを経てマージされて修正完了しています。
また、分散データストリーミング・プラットフォームとして広く使われているApache Kafkaでも、同様にコピー元のクラス名のままとなっているコードを見つけました。こちらもメンテナーに連絡し、バグ認定されて無事に修正完了しています。

※Sider Scanの実績については、公式サイトの「実際のバグ例」にたくさんのケースが掲載されています
大東 : この辺りは、一見シンプルなアルゴリズムに見えますが、単純に抽出するというわけにもいかなさそうですね。
浅原 : おっしゃる通り、単純に変数名やクラス名の一貫性の欠如を抽出しただけでは、大量の偽陽性情報が出てきてしまい、貴重なバグ情報が埋もれてしまいます。そこでSider Scanでは、大量に出てきた疑陽性情報を、機械学習やヒューリスティックなルールを含む10種類以上の独自の手法でふるいにかけています。言葉でいうと簡単なのですが、これは結構泥臭い作業でして、疑陽性情報をSiderのエンジニアみんなで一つひとつ見ていき、どのようにしたら効果的にノイズ落としができるか、日々ディスカッションし、アルゴリズムに落とし込んでいます。一応の目安として、Sider Scan の出す指摘のうち、
- 優先度HIGH は70%以上
- 優先度MIDは30%以上
- 優先度LOW は10%以上
が、バグなどのユーザーにとって有益な指摘となるように設計しています。しかし、逆に言うと、優先度MIDであっても7割は偽陽性ということになります。今後、更に精度を高めていくための取り組みを進めています。
大東 : 今回は、Qiitaのコードチェックという観点で指摘に対する○×を付けたのですが、誤検知だったものと助かったものとで評価をフィードバックして、次回以降の検知でさらに改善する流れができると、さらにいいなと思いました。検出精度の向上が、僕たちにとってもプラスになると思いますので。
浅原 : まさにそのようなお話を多くの方からいただいていますし、私たちもそのような良いフィードバックループで進めたいと考えています。現在はオープンソースコードや、開発に協力してくださる一部のお客さまのコードを活用してSider社のエンジニアが手動で解析エンジンを最適化しているのですが、それをある程度自動でフィードバックを得て、解析エンジンを自己改善していく形に変えつつあります。
具体的には、先ほどのメール画面の「CIサーバーで詳細を見る」ボタンの押下状況や、押下先の滞在時間やスクロール情報などといった利用状況に関するデータや、その他のメタ情報等をいただき、ユーザーにとっての「有益な情報」とは何なのか、自動で学習する形で解析エンジンを最適化していきます。
もちろん、そのようなデータの提供がNGの会社さまもいらっしゃると思うので、その場合はプロフェッショナル版をお使いいただければと思います。また、フリー版であっても、我々が取得する情報はあくまでも利用状況のデータであって、お客さまのソースコード自体は弊社が閲覧・取得することは絶対に無いので安心してご利用ください。

Sider Scanには無償で使える「Free版」と月額費用を支払うことで使える「Professional版」がある。料金価格表ページはこちら
ぜひ常駐監視ツールとして使ってほしい

大東 : 今後の方向性についても伺おうと思っていましたが、今おっしゃったことが今後の目標になりそうですね。
浅原 : そうですね。ユーザーさまからのフィードバックをもとに、より有益な指摘が出せるように、解析エンジンを日々改善していくことが当面のミッションになります。実際に、Sider Scanではほぼ毎週新しいバージョンをリリースしています。毎週少しずつ賢くなっていくSdier Scan にご期待していただきたいです。
大東 : ちなみに、品質管理という観点では、他にも様々なソリューションがあると思うのですが、それらとの使い分けはどう考えれば良いでしょうか?
浅原 : 他の静的解析ツールやテストツールを全てSider Scanに置き換えようと思っているわけではありません。例えば、これまで使っていたLinterやテストツールには無かった「類似コードのパターン分析」という別な視点から、コードレビューを行うツールとして、併用していただきたいです。
大東 : なるほど。最後に、導入を検討している企業に向けて、どのように活用をすると良いかのアドバイスをお願いします。
浅原 : Sider Scanは、「バグを見つけるツール」としてユーザーさまに認知されています。それ自体は間違いではないのですが、どちらかといえば「バグを予防するツール」になると考えています。
お使いのプロダクトの多くはすでに世の中にリリースされているでしょうから、バグそのものは少ない状態があるべき姿だと思います。しかし、開発メンバーの入れ替わり等で今後バグの種が生まれる可能性はあります。
インストールして1回使っただけでは、バグが見つからないこともあると思いますが、是非、1ヶ月から数ヶ月、ある程度の期間利用いただきたいと思います。そうすれば、日々開発を進める中で、思いもよらぬバグを検出することもあると思います。フリー版は、利用期間に制限無く無料で使っていただけるので、ぜひ常駐監視ツールとして、継続して活用していただければと考えています。
編集後記
もともとSider Scanはデスクトップ版とサーバー版に分かれていたようなのですが、デスクトップ版ではクライアントPCのスペックによってはどうしても処理中にPC全体が重くなる弊害があり、サーバー版に一本化したとのことでした。マシンスペックに左右されず毎日実行できる静的解析ツールということで、対談にもあった「開発期間が長く、多くのメンバーが携わっていて、メンバー間のスキルにバラツキがある」ようなプロジェクトのPMは、ぜひ活用を検討してみてはいかがでしょうか。
取材/文:長岡 武司