
オンライン処理で数千万、数億件のデータを扱うようなシステムでは、本番稼働前の性能テストですべての問題を検出しきることは難しいものです。いざ本番稼働を迎えると、データ分布がテスト時と異なり、期待したようなパフォーマンスが出ないことも。
2023年10月に開催したQiita Conference 2023 Autumnでは、Microsoft Azureで稼働するものとしては国内有数の規模のシステムにおける、データベース関連のトラブルや実施している「クエリ診断」の実際について、株式会社野村総合研究所/ NRIデジタル DXエンジニアリング チーフエキスパートの湯川 勇太氏に紹介していただきました。本記事では、その内容をお伝えします。
プロフィール

NRIデジタル DXエンジニアリング チーフエキスパート
前職では大手日系SIerにて、PM兼アーキテクトとしてECモールの設計運用を8年担当。担当したECモールは年間売上が10倍に拡大した。
入社後は大手物流企業の配送システムの技術検証、方式設計、トラブル対応を担当。このシステムはAzureで稼働するものとして国内有数の規模となっている。
「職人芸」でトラブルを鎮めることが多々あった
湯川: 私が出向しているNRIデジタル株式会社は野村総合研究所グループのデジタルビジネスの専門会社で、デジタル化戦略の構想から、先端ITソリューションの選定・構築、事業の実行支援、プロジェクト全体の検証・改善にいたるまで、顧客企業のデジタルトランスフォーメーション(DX)をトータルで支援しています。
例えば、支援している大手物流企業さまで「技術ガバナンスチーム」を組織してグループ全体のITに関する戦略企画、標準化、品質管理、コスト管理、重度障害対応などを実施しています。私はこのチームで複数のプロダクトの方式設計や技術検証、解決が難しい障害の調査などを担当しています。
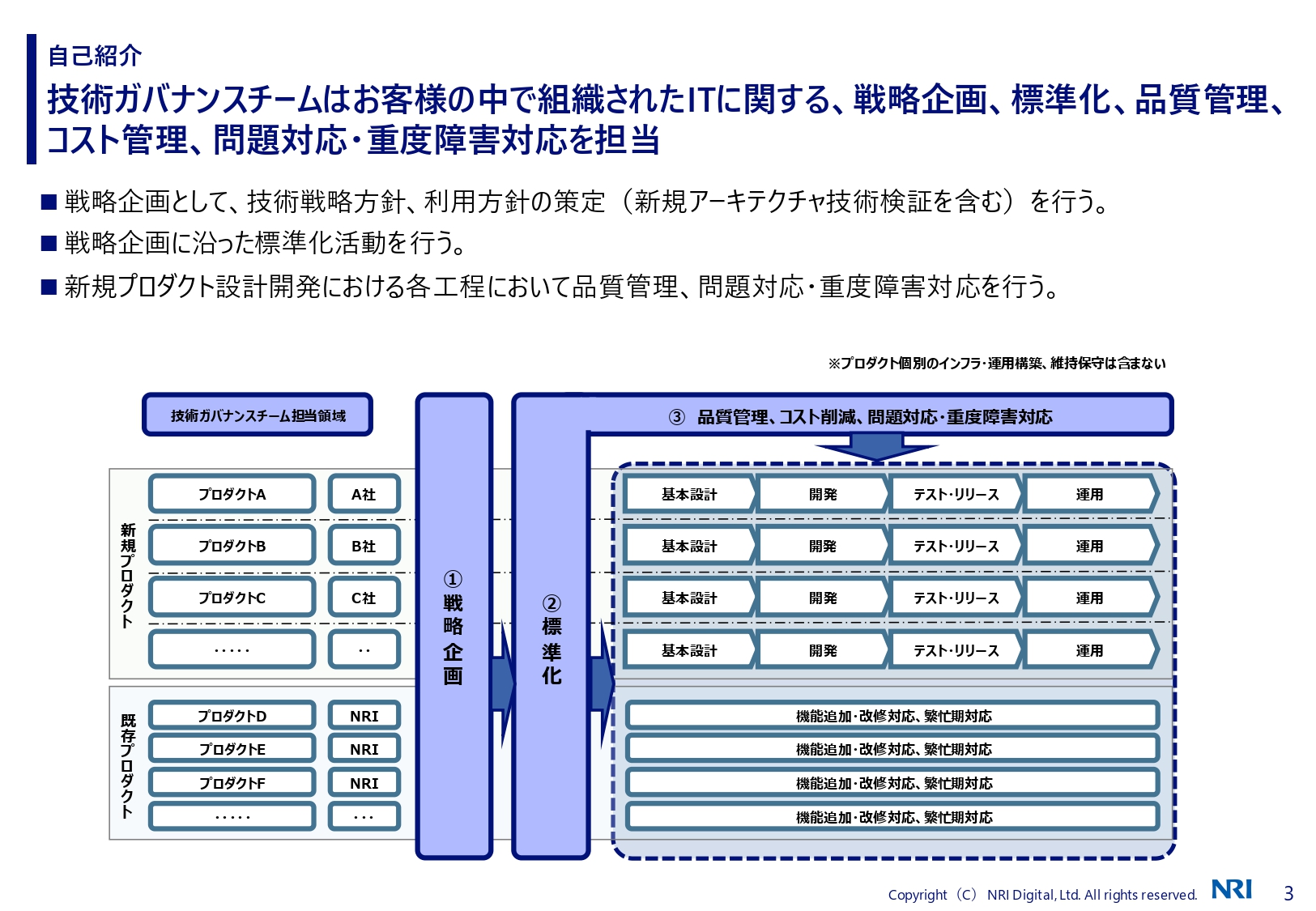
湯川: 今日は、この技術ガバナンスチームが行っている活動の1つ「クエリ診断」をご紹介します。
はじめに、クエリ診断活動が誕生した背景からお話させてください。
この物流企業さまではシステムを開発・運用している中で、データベース関連の性能問題が多数発生してしまっていました。背景としてはオンライン処理で数千万件、数億件のデータを扱うようなシステムが多いことから、小規模なシステムであればマシンパワーでごまかせてしまえるような問題でも、顕在化しやすい状況があります。
性能問題の主な原因についてご説明します。
まず、「データの分布が開発時に想定していたものと実際の本番稼働後の実データでは異なっていた」というケースです。
新しいシステムを使った新しい業務が始まるような場合には、そもそも以前から使っていたシステムのデータが存在しません。そのため、テストデータを想定で作るのですが、このテストデータのデータ分布が実際と異なっていたために、開発と本番で異なる実行計画が生まれ、結果として開発環境では問題が発生しなかったクエリが本番では問題を起こしてしまいました。
そのほかの原因としては、クエリと一緒に指定しているパラメータの値に最適な実行計画が依存していて、その値が偏ったものだったときに、典型的な値のパターンにとっては不適切な実行計画になってしまうことがあります。このケースでは急に性能が劣化するので「昨日まで順調に動いていたのに、一体どうしたんだろう?」という騒ぎになります。これは後ほど、ご説明します。
残念ながら、どんなにテストを頑張っても本来は開発時に気づくべき問題を潰しきれないこともあります。
とても多くの人数で並行して複数のプロダクトを開発していることもあり、プロジェクトの期間や確保できているメンバーのスキル、それまで経験してきたデータベース製品との違いなど、人に由来する様々な制約によって潰しきれないことがあります。より単純に時間がなくてテーブルを設計する際に性能まで意識できなかった、あるいは単純にインデックスの理解が足りておらず設計が誤っていた、というようなことが原因で問題が起こることもあります。
データベースでトラブルが発生するとどういう状況になるのか。実際にこんなことがありました。
私が朝、保育園に子供を送り届けてから会社の携帯を見てみると、たくさんの着信履歴があり、「このZoomに入ってください」というメッセージが残っていました。Zoomに入るとトラブルになっているようで、お客さまも集まっていました。お客さま役員の方からは「今、どこまで分かったのか?」「アプリは何をやっていてインフラは何をやっているのか?」といった状況説明を求められ、事象の切り分けのために「一旦、フェイルオーバーさせていただけませんか?」と伺っても、なかなか許可していただけない状況でした。

湯川: 薄い文字で愚痴のようなことも書いていますが、お客さまの立場からすると、完全にシステムがダウンしているのなら思い切った判断もできると思いますが、曲がりなりにも動いていて原因が分かっていない状況の中で思い切った判断を下すことは、なかなかできないものです。
パブリッククラウドでは、障害でなくても日々フェイルオーバーは発生しています。しかし、想定外の状況でフェイルオーバーすることで、「もっとひどい状況になったらどうする?」という発想になるのは当然と言えば当然です。
そのような緊張感の中で何とか情報を拾い集めながら、これが原因ではないかというものを突き止めて、職人芸的に対策を実施してトラブルを鎮めるような事象がたびたび発生していました。
そこで技術ガバナンスチームでは年に2回、「クエリ診断」というデータベースの健康診断のようなものを行うようになりました。
自社で作成した診断ツールで問題クエリを検出
クエリ診断作業の進め方~評価フェーズ
湯川: ここからは、クエリ診断の具体的な進め方を説明します。クエリ診断は自分たちで作った診断ツールを使って機械的に行う「評価フェーズ」と、アプリケーションの観点を交えながら個別に検討を行っていく「優先順位付けと対策フェーズ」の2段階の分かれます。
評価フェーズは技術ガバナンスチームが中心になって実施します。優先順位を付けたり対策を検討したりするのはプロダクトが中心で、技術ガバナンスチームは技術的な観点からの支援を行うという役割分担で進めています。
評価フェーズでとても頼りにしているのが、SQL Server 2016以降に実装されている「クエリストア」という仕組みです。これはクエリやプラン(実行計画)、実行時の統計情報を保存して、後で調査できるようにしてくれるものです。
このクエリストアを抽出して、自分たちで作成した診断ツールにかけて1次切り分けを行います。まずはクエリとプランのみで、ざっくりと判断を実施するのです。
その後にアプリケーションのソースと突き合わせて、オンライン処理なのかバッチ処理なのか、あるいは実行頻度などを加味して精査します。次に優先順位を付けてインデックスやクエリの見直しをしたり、処理のバッチ化をしたりといった対策を実施していきます。そして最終的に、検討した対策を本番環境に適用していくというのがクエリ診断作業の流れです。

クエリ診断作業の進め方~クエリ診断ツールと診断ポイント
湯川: 先ほど触れた自分たちで作った診断ツールですが、これを使えばクエリストアを基に、実行計画に特定の条件が含まれるものを「問題クエリ候補」として検出できます。また、後のステップで優先順位を付けたり検討したりしていくために必要な情報として、クエリテキスト、実行計画、最大CPU時間、最大抽出件数、実行回数、クエリが利用しているインデックスなどを抽出できるようになっています。
問題があるクエリを検出するときの観点として一番重視しているのが、読み取りの「最大論理行数」です。例えば、最終的に100万件抽出するもので、途中の読み取り件数が110万件であるようなケースの場合は必ずしも問題だとは言えません。ところが、最終的な抽出件数に対して読み取り件数がとても多い場合には、「絞り込み条件の指定が足りない」「適切なインデックスの不足」といった問題が含まれる可能性があります。
加えて「インデックススキャン」や「クラスタ化インデックススキャン」といった観点も重要視しており、これによってデータを扱うときの参照の仕方が不適切なものを抽出できます。これらが抽出される場合は、適切なインデックスが定義されていないか、クエリの問題でインデックスが利用できない状態が発生している可能性があります。
「ハッシュ結合」や「マージ結合」も問題クエリの候補として抽出対象としていますが、これらの利用はやむを得ない場合もあり、参考情報として扱っています。
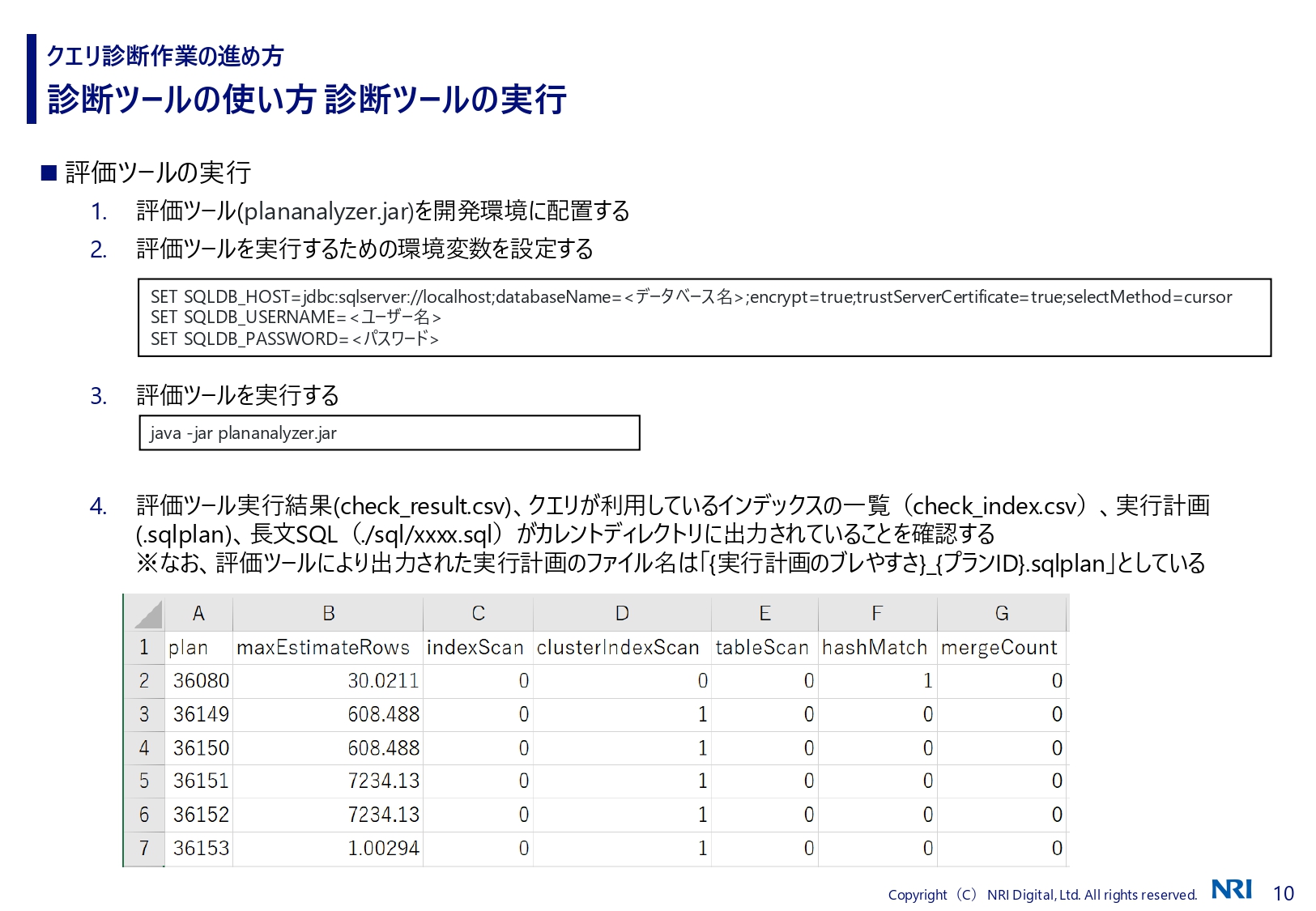
診断ツールの使い方も簡単にご紹介しておきます。大きな流れは、評価用の環境にSQL Serverを入れて、クエリストアを取り込んだ後、ツールにかけるという手順です。
診断ツールはJavaで作っているので、接続先の情報を環境変数に渡して実行するとファイルが出力されるようになっています。こちらの図ではSQL文のところを省略していますが、実行計画のプランのIDや論理行数などはCSVファイルに出力されます。評価するときは、それをExcelで開いて人間が見ています。

クエリ診断作業の進め方~優先順位付けと対策フェーズ
湯川: 残念ながら、すべてのクエリを確認することは困難です。そこで3つの観点から優先順位付けを行って対応を進めています。
1つ目の観点は、リソースの使用量です。優先的に確認すべきクエリは、診断ログから次の観点で上位にランクインするものです。
- 最大CPU時間が長い…一般的に性能問題として最初に検出される
- 最大論理読み取りの量が多い…CPU時間よりも極端に違いが出る
- 最大結果行数が多い…CPU時間が短く、DBにとっては負荷になっていなくても、アプリのメモリや応答時間を劣化させる
- 最大物理読み取りの量が多い…tempdb に溢れている
- 合計CPU時間が長い…DBに負荷をかけている
- 最大処理時間が長い…最大CPU時間が短く、処理時間が長い場合は何らかの待機で他のクエリの影響を受けている
- 実行回数…対策優先順位を決める際に利用する
2つ目の観点は実行計画です。優先的に確認すべきクエリは、実行計画がブレやすいものです。この評価ツールで出力された実行計画のファイル名は、先頭が「実行計画のブレやすさ」で始まるように命名しているので、ファイル名の先頭の数値が大きいものから確認しています。
3つ目の観点は処理区分です。優先的に確認すべきクエリは、オンライン処理のものです。オンライン処理で発行されるクエリでの1分はかなり長いですが、バッチ処理なら問題ない場合が多いためです。
さらにオンライン処理のクエリであれば、CPU時間や論理読み取りの量が多いものの優先順位を高くします。バッチ処理については、リソースの使用量が多いものや実行回数が多いものを中心に潰していくような優先順位付けをしています。
優先順位付けが終わると、次に対応方針を決めます。「そんなことか」と思われるかもしれませんが、問題クエリの原因としてよくあるのは「適切なインデックスが定義されていないこと」です。この原因に対する対策は「インデックスを追加する」となります。
また、インデックスがあったとしても、インデックス列に対して演算や関数を適用するなど、インデックスが利用されていない記法となっている場合があります。この場合には、インデックスが利用されるように記法を見直します。
もう1つ、通常は問題のない実行計画で処理されているクエリが突然異なる実行計画に変化してしまい、著しい性能劣化を引き起こすこともたびたび発生します。この問題はパラメータによって大きく実行計画が変わり得るようなクエリで発生します。こうした問題を引き起こすクエリについては、SQL Serverが持っている「プラン強制」の仕組みを利用して実行計画を固定したり、ヒント句を使ってなるべく人間の意志が反映された実行計画となるように直したりします。
プラン強制とは、クエリストアに保存された実行計画の中で、人間が選択しフラグを付けたものを優先的に使わせる仕組みです。本番環境で性能問題が発生した場合には、アプリケーションのリリースをせずに対応できるため、非常に強力な武器になります。
ただし、過去に問題のない実行計画が作られた実績がないと利用できません。また、ORやINで指定されたパラメータ数も含めて完全に一致していないと、同じクエリと見なされないため注意が必要です。
対応力を養う勉強会を社内で実施
対策の検討~アクセスパス設計
湯川: 対策の方針が定まったところで、続いて対策の検討に進みます。技術ガバナンスチームでは、より多くの人が診断を基に対策を検討できるように、「アクセスパス設計」について勉強会を開催するなど、啓蒙活動のような取り組みも行っています。
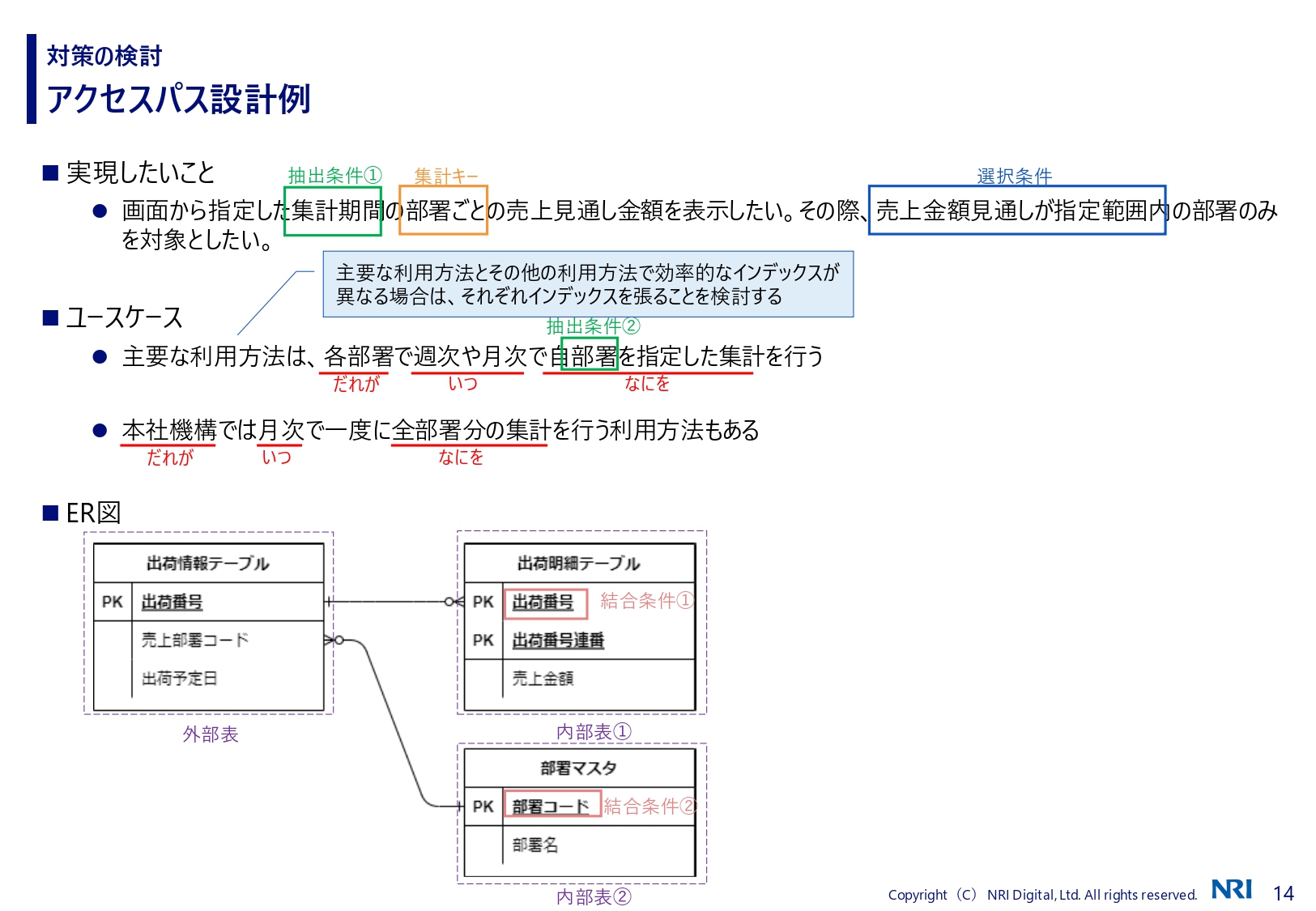
アクセスパス設計のおおまかなステップは、次の5つです。
- ユースケースの洗い出し
- だれが、いつ、なんのために利用するのかを明確にする
- 検索条件の洗い出しや利用頻度に応じた適切なインデックス設計の検討に役立つ
- データモデルの作成・見直し
- 外部表・内部表および抽出条件の決定
- 各テーブルのレコード数、抽出されるレコード数、各項目のカーディナリティを把握する
- ※外部表:最初にアクセスされるテーブル(別名:駆動表)
- ※内部表:外部表に対して結合されるテーブル
- ※カーディナリティ:テーブルの項目に含まれる異なる値の数のこと。「カーディナリティが高い」とは同じ値が入ることが少ないという意味。例えば「荷物ID」が該当します。一方で、「カーディナリティが低い」とは同じ値が入ることが多いという意味で、性別などが該当します。
- 外部表と内部表の結合条件の決定
- 外部表の1レコードに対して結合される内部表のレコード数を把握する
- インデックスの決定
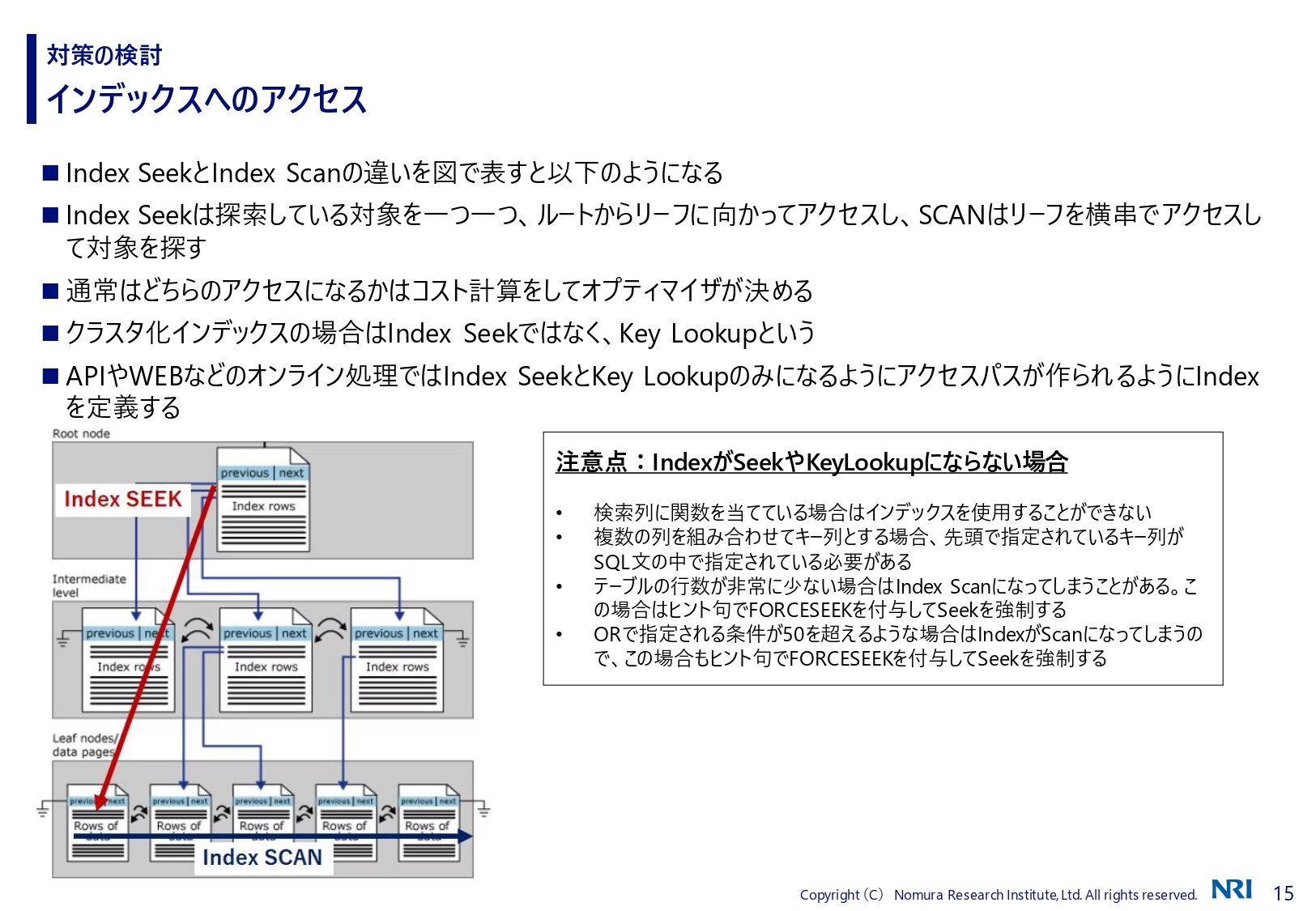
湯川: SQL Serverの場合、インデックスへのアクセスパスはIndex SeekとIndex Scanの2種類があります。勉強会では、期待通りのパスをオプティマイザに選んでもらえないケースを示しながら、実行計画をどのように修正すればいいのか、見るときのポイントは何なのかといった説明をして、対応力を身につけられるようにしています。
対策の検討~実例からパラメータスニッフィングについて考える
湯川: 先ほど、指定されていたパラメータによって実行計画が大きく変動してしまうようなケースがあると話しましたが、ここでもう少し詳しく説明します。
これは、クエリがコンパイルされるときに指定されていたパラメータが特殊なものだった場合に、不適切な実行計画になってしまう「パラメータスニッフィング」と呼ばれる問題です。
オプティマイザはクエリをコンパイルするときに、与えられたパラメータを基に実行計画を作っています。しかし、その時点では指定されていない複数のパラメータも含めて総合的に判断してくれるわけではありません。1度たまたま指定されていたパラメータを元に作られた実行計画ができて、それがキャッシュされます。このときに指定されていたパラメータが特殊なものだった場合、次の実行計画が作られるタイミングが訪れるまでの間は性能問題を引き起こすことになります。
新しい実行計画が作られるのは、主に次のような契機です。
- 明示的な手動リコンパイル
- 正確性に関連する自動リコンパイル(スキーマ変更、リコンパイルの必要性のあるSETオプションの変更)
- 最適性に関連する自動リコンパイル(データ更新に伴う自動統計更新、明示的な手動統計更新、Indexの再構築)
- プランのキャッシュアウトに伴うリコンパイル(プロセス再起動、メモリ負荷、フェイルオーバー、スケールアップダウン)
パラメータスニッフィングによる問題は、NRIが支援しているシステムでも、たびたび発生してきました。こちらに示しているのは、まったく同じクエリでも与えられるパラメータによって全然違う実行計画になってしまう例です。

湯川: こちらの図にsales_persion_id = 0とありますが、大多数のデータが0なので大して絞り込むことができません。そのため0が指定されると、右側のようにClustered Index Scanとなり、テーブル全件を舐めてしまうのです。これがキャッシュされてしまっていると0以外のパラメータが指定されたときも、この実行計画で動いてしまって、非常に時間がかかってしまうわけです。
もし、パラメータが最初に実行計画が作られるときに指定されていた285だったなら、きちんとインデックスを使って絞り込みを行った後で、足りない項目をKey Lookupでクラスタ化インデックスに取りに行って、その結果を返す動きをしてくれたはずです。
このように、人間が期待するのはパターン1なのに、指定されているパラメータによってはパターン2が出てしまうことがあります。
クエリストアのプラン強制を使うと、こうしたケースで使いたいパターンを名指しで指定できます。
ただし、プラン強制が万能ではないことは、先ほど問題クエリの対応検討のところで紹介した通りです。
ORやINで指定されているパラメータ数がアプリケーションの中で可変になっていて、複数増えたり減ったりするようなするような場合には、パラメータの数が一致している場合と同じクエリだと見なされません。そのため、プラン強制で対処するのが難しいことがあります。そういうケースではヒント句を書いて、人間の意思を反映させます。
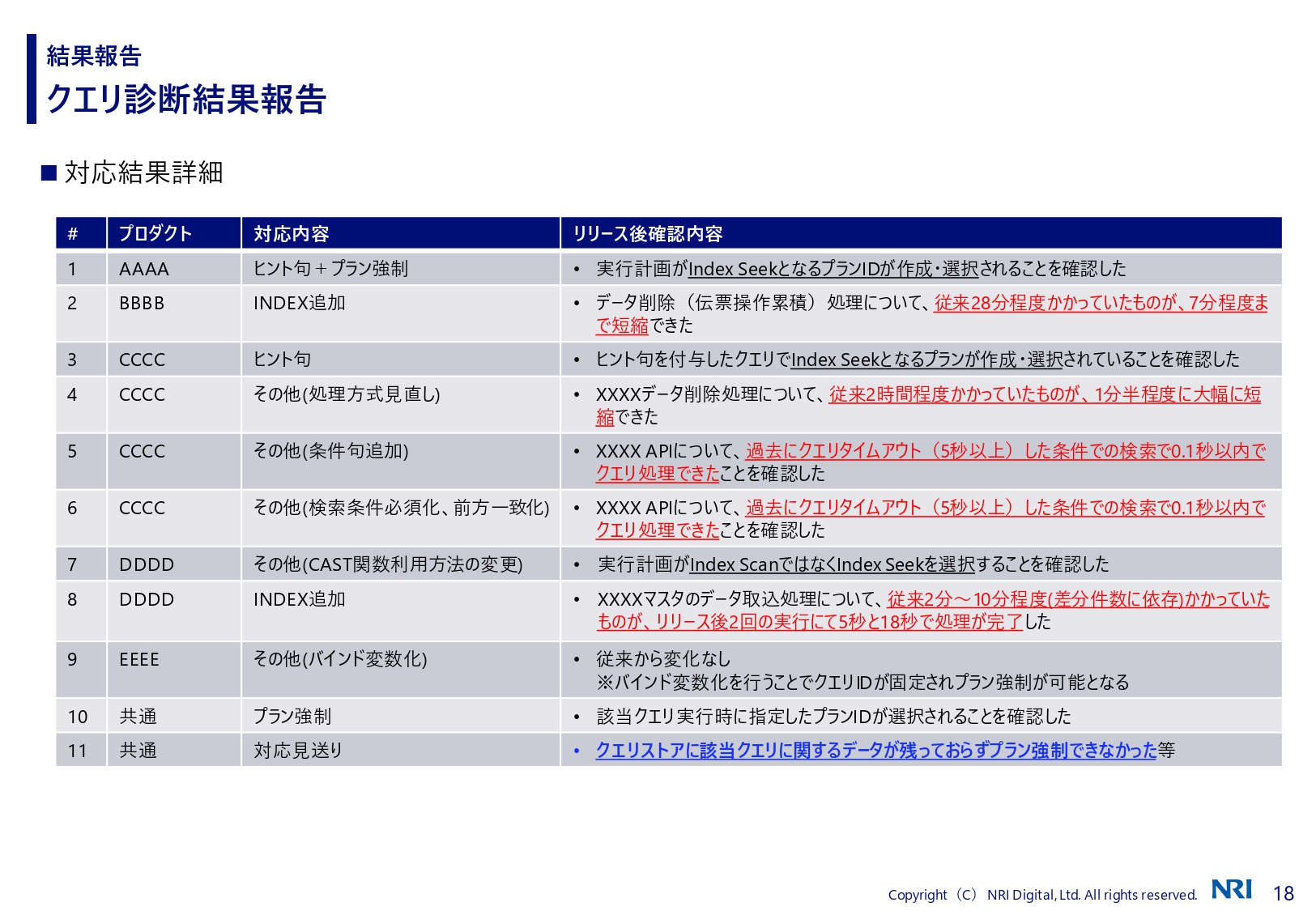
結果報告には「対応見送り」も
湯川: こうした対策を、時間をかけて1つひとつ検討して潰していき、最終的に繁忙期の前に、どのプロダクトでどのような対策を行ったのか、リリース後は何を確認したのか、どれぐらいの効果が見られたのかをお客さまに報告しています。
結果報告の中には「対応見送り」もあります。クエリストアに該当のクエリが必ずしも残っているとは限りません。そもそも検出できてない、あるいはプラン強制したくともできなかった、ということもあるのです。
このような理由もあって、作業時間が十分にあったとしてもすべてに対して対策しきれるわけではないため、クエリ診断は1度で終わりではなく年2回を継続して実施しています。
クエリ診断に関してのご紹介は以上です。
湯川: 最後に注意事項です。ここまでお話ししてきたのはSQL ServerやSQL Databaseの場合を前提にしています。基本的な考え方は似ているとは思いますが、他のデータベースにそのまま適用できません。
SQL Serverの場合は、テーブルにクラスタ化インデックスを定義することが事実上必須です。また、同じ用語でもデータベースによって意味が異なる場合があります。例えばIndex Scanはインデックスのリーフを横串で参照することを言い、ルートからリーフに向かうアクセスのことではありませんので、ご注意いただければと思います。
課題をエンジニアリングで解決したい方へ
湯川: 1点お知らせです。NRIでは、キャリア入社でNRIへジョインいただける方を募集しています。ご自身のスキルと経験を生かして、顧客や社会の課題をエンジニアリングで解決したい方や、より大きなシステムの構築にチャレンジしたい方などを募集しています。今後のキャリア形成にぜひご検討ください。
休日での1Day選考会も実施しています。オンラインで、しかも1日で選考がすべて終わりますので、こちらも合わせてご検討・ご活用ください。
文:ノーバジェット