
海外にも多くの研究フィールドを持つ日立製作所。同社は海外機関との共同研究プロジェクトをいくつも走らせており、これまでQiita Zineでも当事者である研究者にお話を伺ってきました(参考記事はこちら)。
社会実装先としての会社アセットを前提としつつ、例えば海外研究機関や大学などの教育機関の研究室等にジョインできる。これは、研究者として非常に魅力的なキャリアと言えるのではないでしょうか。
本記事では、「XAI(説明可能AI)」と「NLP(自然言語処理)」をテーマにスタンフォード大学との共同研究を進めてきた2名の日立メンバーに、それぞれ具体的な研究内容や将来的な社会実装イメージ、研究フィールドとしての魅力などを伺いました。
目次
プロフィール

研究開発グループ メディア知能処理研究部 主任研究員

XAIを高信頼化する適用条件を明確化していく

――おふたりともスタンフォード大学との共同研究をなさってきたということで、具体的な研究内容とそこに至るまでの経緯について、それぞれ教えてください。まずは間瀬さんからお願いします。
間瀬 : 2019〜2021年の間、スタンフォード大学の客員研究員として従事しました。テーマは、XAIの統計学観点からの理論研究です。
――XAI領域の研究は、それ以前からされていたのでしょうか?
間瀬 : はい。日立はこの領域の研究を2017年頃から行っており、いくつかビジネスへの適用を検討していく中で、XAIの有効性に着目してきました。
しかし、論文の技術をそのまま適用すると理論的な適用条件で分からない部分があったり、計算処理が重いといった実装上の課題が見えてきました。
一度理論に立ち返って、より信頼できる形にできないかということを研究チームで議論していたところ、スタンフォード大学のArt B. Owen教授(以下、Owen先生)の存在を知り、共同研究を進めていくことになりました。
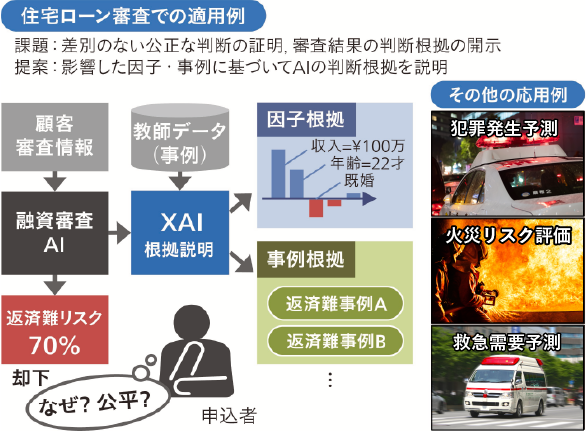
AI判断の根拠説明技術(XAI)の応用例
――なぜ、Owen先生だったのでしょうか?
間瀬 : ブラックボックスの根拠となる因子が何かを分析するアプローチの1つにシャープレイ値(※)という協力ゲーム理論に基づく手法がありまして、これが理論的な裏付けからきっちり定義されていることがあり、我々としても注目していました。Owen先生は「シャープレイ値」を統計的な分析へと利用する論文を書かれていて、その内容がXAIの研究に活かせるのではないかと考え、共同研究を打診したところ、ご快諾いただき、客員研究員としてスタンフォード大学に滞在して共同研究を進めていくことになりました。
――なるほど。あらかじめ用意されていた客員研究員の話ではなく、ご自身の研究の過程で進んだ話だったのですね。実際に取り組まれた研究内容についても教えてください。
間瀬 : 取り組み内容としては、XAIを高信頼化するための適用条件を明確化していくというものです。
もともと統計学の分野では、ブラックボックスの解析が古くから行われてきました。例えば、プラントの制御やウイルスのDNA配列のどの部分がどのような作用に影響しているかなど、実世界の様々な部分で統計は使われています。
ブラックボックスを解析する際は、「どの変数が重要かをしっかりと定量化する」ことが最初のステップになります。
そして「どの変数が重要かを定量化する」ために、大量のデータを集め、その中で分散を計算する手法が統計学ではよく用いられます。
分散というのはバラつきのこと。「ある変数の値がバラついたときに、それが全体のブラックボックスの出力のバラつきにどれだけ寄与するか」ということが数十年間研究され続けています。
これが物理現象ではなく、AIの振る舞いになった場合にどういう手段を取るべきか。これをテーマに研究しており、AIの振る舞いの解析では分散ではなく予測結果の値への因子ごとの寄与を計算するのですが、シャープレイ値をAIの振る舞いに対して適用する際に、より統計的に妥当な設定にしたような手法として共同で開発しました。
シャープレイ値:Shapley value。ゲーム理論において、協力によって得られた利得を各プレイヤーへと公正に分配する方法。
AIの公平性をどう考えるべきか
――シャープレイ値を使った手法ということで、具体的にはどういうものなのでしょうか?
間瀬 : 既存のXAIの手法の多くは、AIは完璧なものであると仮定してAIへの入力を変えながら感度解析をしていき、どの変数が重要かを定量化していくアプローチです。
ただ、あらゆる条件のデータに対して高信頼な出力を得られるAIを作ることは現実にはなかなか難しいものです。
それを解決するために、観測したデータの範囲内だけで変数の重要性を定量化する手法を実現できないかという議論をOwen先生と進めていきました。
その中で、「コホート・シャープレイ(Cohort Shapley)」という新しいXAIの技術を開発しました。これを使うことで、既存のXAIアプローチの結果との違いを深く議論できるようになります。
また、近年ではAIの説明性の他に「AIの公平性」も非常に重要なトピックになっています。公平性を考える際にもコホート・シャープレイは有用です。
例えば、差別につながるような因子を入力していなくても、実際に外から観測するとそのように見えてしまうような事態が起きていないかを、コホート・シャープレイを使って分析することができるようになります。
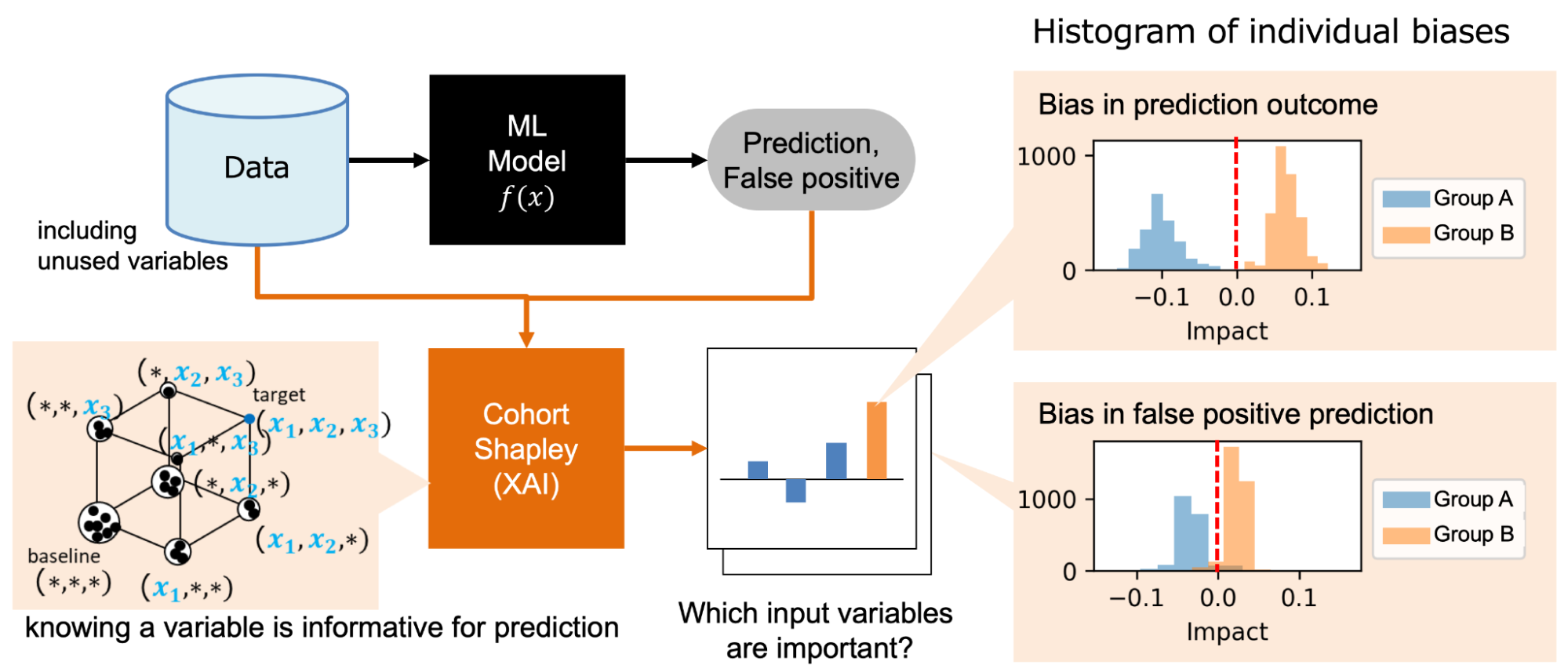
コホート・シャープレイでは、予測結果や予測の偽陽性等の様々な観点のクラス間の偏りについて、グループ間でのバイアスに加えて、個別事例がどのようにバイアスに寄与しているかを分析する
――今「公平性」のお話がありましたが、公平という概念は非常に定性的で、教科書的な正解がない領域だと感じます。この公平性をAIで考えるにあたって、具体的にどのような議論や考え方をなさっていったのでしょうか?
間瀬 : おっしゃる通り、非常に難しい問題です。
Owen先生と公平性について議論していた中で、スタンフォード大学の統計学科には公平性の論文の輪講の授業があり、それを受けてみてはどうかという話になりました。
その授業では数学の論文だけでなく、公平性の問題がありそうなニュース記事を読んだりもしました。
具体的な事例をもとにディスカッションするわけですが、例えば当時はCOVID-19が広がり始めたタイミングだったので、人工呼吸器が足りないときにどう配分するとより公平なのか、といったことがテーマになりました。さらには公平や正義(justice)とは何かを考えるような哲学の論文も読みます。
そのうえで、公平性の機械学習の論文を読んで、ケースに応じた手法などをディスカッションしていく流れでした。
――難しそうですが、非常に面白そうですね。
間瀬 : 公平性にも様々な考え方がありますが、その1つは例えば「全員が平等ではないということを認識した上で、弱者が不利益を被らないような振る舞いをするのが公平だ」というものです。
もちろん他にも公平に対する様々な考え方があって、常にディスカッションをしながら社会的な議論をしています。AIの公平性を考える上では、それをさらに数学の定義に変換する必要があるわけです。
何を公平とするのか、機械学習の予測結果のデータからどのように定量化された指標を作成するのか、いかにその指標を継続的に改善していくのか。
今日ではこのようなことについて、個別の事例ごとに踏み込んで活発に議論されています。
日立でも、2021年2月に「AI倫理の基本原則」を公開しています。技術で解決できる部分は、我々研究者が理論的な裏付けを進めています。それだけでなく、広く社会一般の皆さまにも、正しくAIを理解していただきながら、AIの社会実装していく取り組みもしています。
リーガルテックから考える自然言語処理のあり方

――次に是枝さんも、具体的な研究内容とそこに至るまでの経緯について、それぞれ教えてください。
是枝:私は大学との関わり方が間瀬さんと違っています。北米での自然言語処理技術の開発とオポチュニティ探索のミッションで2020年に日立アメリカへと出向し、そのタイミングでスタンフォード大学との共同研究を開始しました。
日立は自然言語処理にも力を入れていることから、Christopher D. Manning教授(以下:Manning先生)との共同研究を進めることになりました。
――スタンフォード大学のNLPグループには多くの教授がいると思いますが、なぜManning先生だったのでしょうか?
是枝:Manning先生は、ニューラルネットワークを自然言語処理に応用することにおいて非常に著名な先生です。そして、研究成果をソフトウェアの形で社会へとフィードバックしていることが非常に特徴的な方です。よく知られているものとしては、「Stanford CoreNLP」と呼ばれる自然言語処理ツールが挙げられますね。
私の研究している内容が社会実装を重視していたこともあり、Manning先生との共同研究をお願いすることにいたしました。
――社会実装の重視とは、どういうことでしょうか?
是枝:背景からお話しできればと思いますが、昨今ではリーガルテック(Legal Tech)の中でも「契約書の読解支援」が非常に盛んになっています。
弁護士やパラリーガルの方が契約書の確認作業に多くの時間を割いており、なかなか創造的な仕事に時間を割くことができていないというのが、その理由です。これは大きな社会課題であると認識しています。
また、もう1つ忘れてはいけないのが、多くの個人や小さい企業は法律サービスに十分にアクセスできていないということです。それにより、契約書を読んでもよく分からずにそのまま同意をしてしまうということは往々に発生していると可能性もあるでしょう。もちろん、これはビジネスの話ではなく、消費者を対象とするBtoCのサービスでも、同じことが言えると思います。
――どちらも想像に難くないですね。
是枝:現在、様々なリーガルテックサービスが提供されているわけですが、その多くは「何について書かれているか」以上を判断できないという現状があります。例えば、ある条項がここに書かれているというのを抽出してくれるというものです。
もちろんこれだけでも非常に有意義ではあるのですが、具体的にどんなことが実際に書かれているかまでは分からないわけです。自分が許容できない情報があるのかは分からず、結果として契約書を全部読まないと細かい部分までは把握できないのです。
これに対して我々の共同研究では、この問題を解くためにどういう形で定式化するべきか、というところから始めました。
契約書のための文書レベル含意判定技術

是枝:Manning先生は様々な分野の研究をなさっているのですが、その中にNLI(Natural Language Inference;含意関係認識)という領域があります。これは、2つの与えられた文の間に「含意」の関係があるかどうかを抽出するというものです。
――含意とはどういうことでしょうか?
是枝:一言で表すのであれば、「文の表現としては違っていても、言っている意味としては同じものを含むか」を抽出するものです。
考え方としては割とファンダメンタルな言語処理の問題です。これまではあまり応用されてこなかった分野なのですが、これを応用したら面白いんじゃないかということを先生と一緒に話しまして、図にあるような問題に落とし込むことを提案しました。
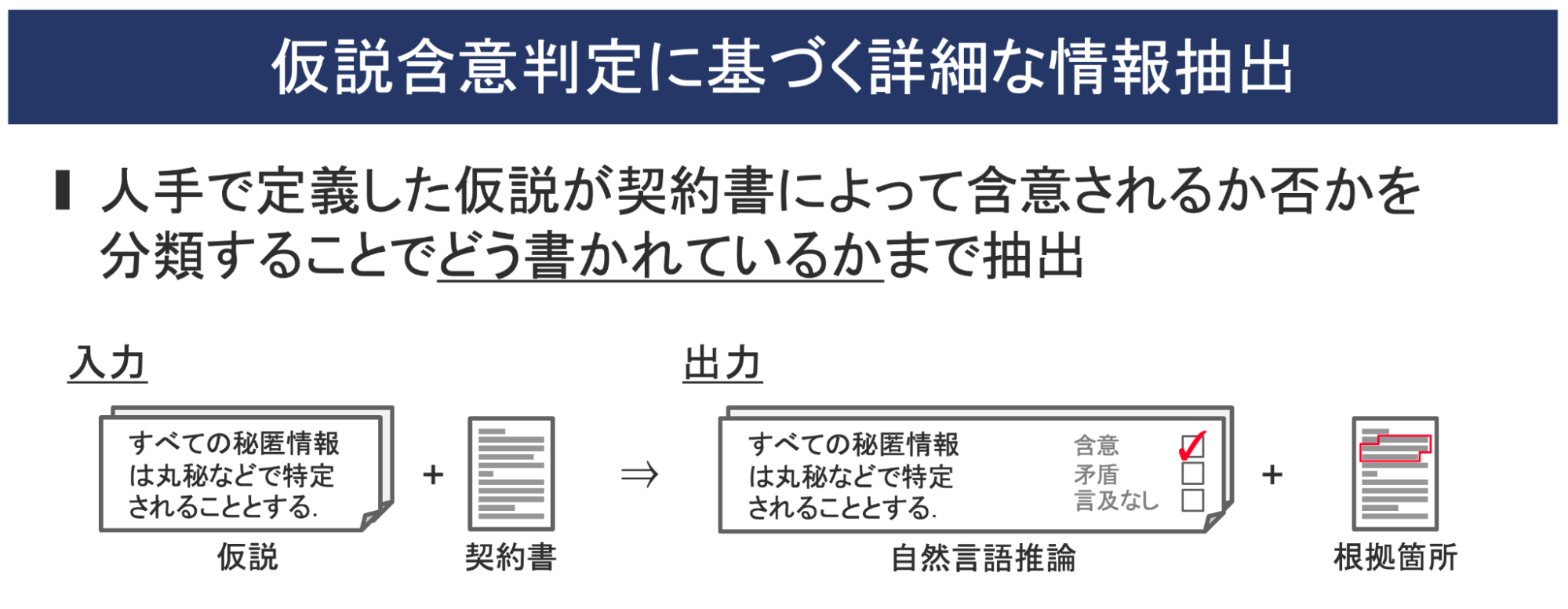
是枝:まずは入力として、仮説と契約書が与えられます。ここでいう仮説とは、例えばNDA(秘密保持契約)であれば「すべての秘匿情報は丸秘などで特定されることとする」などの文章となります。もちろん他にも、例えばBtoCサービスの利用規約であれば「個人情報をデータは第三者に提供しない」といったことも考えられます。
この研究では、今お伝えした仮説と契約書が含意されているのか、逆に矛盾しているのか、あるいは言及されていないのかを判定します。それに併せて、なぜその判断が下されたのかという根拠の部分も抽出・表示します。ここは間瀬さんの研究領域とも重なる部分ですね。
これによって、その契約書が「何について書かれているか」だけではなく、「どう書かれているか」までを抽出できるようになります。この技術を「文書レベル含意判定技術 」と呼んでいます。
――なるほど。
是枝:また、先ほどもお伝えしたとおりツールの形で世に公開するので、Manning先生に助言をいただきながら、まずデータの作成をしました。契約書をネットなどから集めてきて、アノテーションしてフォーマッティングし、1ヶ月前に無事に公開することができました。(https://stanfordnlp.github.io/contract-nli/)

――データを作成するのはわかりますが、なぜ全世界に向けて公開をされたのでしょうか?
是枝:ベースラインの機械学習のモデルを一緒に研究して公開したのですが、この問題は非常に難しく、私1人だけの力ではできることに限界があります。
全世界にデータを公開することで、社会全体の力を使ってこの問題のモデルの精度を上げていくことが可能になります。だからこそ、より広く使っていただけるように研究オンリーという制約を設けていませんし、他の企業でも使えるようにしています。
互いの研究領域をうまく応用して活かしていきたい

――是枝さんの研究内容については、リーガルテック以外でも広く活用できそうですね。
是枝:そうですね。近年では「質問応答」におけるAI活用も盛んでして、質問に対して単語レベルで回答を抽出する形が一般的なのですが、現状では本研究で対象とするような「意味レベルの抽出」は範囲外となっており、質問応答の可能性を広げることにも寄与できるのではないかと考えています。
また、ファクトチェックの領域でも活用ができると思っています。ファクトチェックにおいても、何かしらの主張と文章が与えられていて、それに対する結果として主張が正確か誤りか、もしくは判断不能かを返すことになります。
先ほどご覧いただいた入力と出力の形とほぼ同じであることがお分かりいただけると思います。
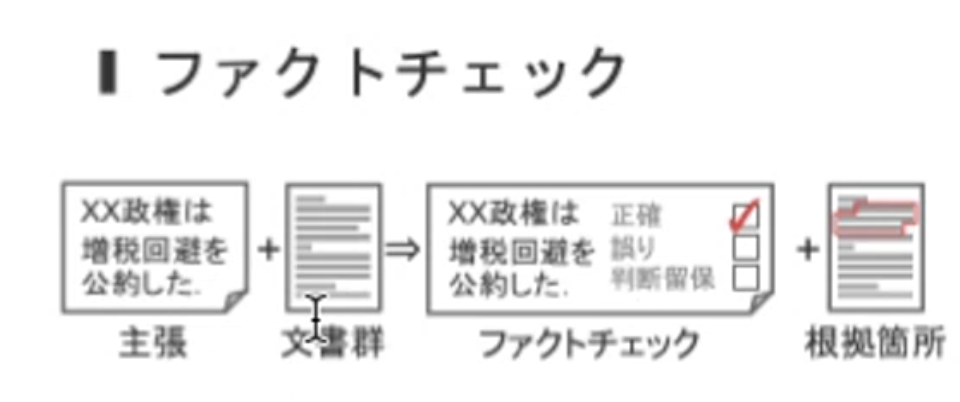
是枝:我々の研究を応用してファクトチェック領域でも活かすことができれば、より大きな社会的な成果を得られるのではないかと思っています。
――いいですね。間瀬さんの研究も、より根本的な部分の「あり方」に関わる話なので、AI活用そのものの基盤的な思想につながっていくように感じます。
間瀬 : そうですね。一般的な話になってしまいますが、AI研究がある理由は、私たちがAIを便利な道具として使うためです。ですので、AIの挙動をうまく制御できずに、人に不利益を与えるようなことが起きないようにする必要があるわけです。
重要なところは人でもチェックできるようにして、例えば「AIのファクトチェック」みたいなものができるようになってくると、社会の中でのAI活用が進み、より豊かな暮らしへとつながっていくだろうなと感じています。

――おふたりの研究はクロスオーバーする部分もあると思うのですが、いかがでしょうか?
間瀬 : 私は帰国してから自然言語処理の研究にも携わり始めていまして、是枝さんの最新技術はとても可能性があると感じています。契約書のようなキチッと書かれた文章だけではなく、例えばブログ記事やWeb上の討論記事など。より柔軟な文章への応用についても、今後ディスカッションできたらいいなと思っています。
是枝:私はあくまで人の支援をしたいと考えています。人を支援してより生産的に活動ができれば、残った時間でもっと別のことができるようになるわけです。
そのためには、今までのやり方を大きく変えずにAI活用を進めることと、間瀬さんがやっていらっしゃるような説明性がとても重要だと思っています。
――研究として連携することはあるのでしょうか?
是枝:これまでは、基本的に研究レベルで交わることはなかったですよね?
間瀬 : そうですね。我々はどちらかというと、AIをブラックボックスと捉えて、その外側で根拠を探していくというアプローチです。一方で是枝さんたちは、根拠も示せるようにアルゴリズムから考えているというアプローチかなと。
是枝:少し乱暴な表現ですが、我々は「できればいいや」的なところに行きがちな部分があると思います。間瀬さんたちのように、そもそも根拠はどうあるべきかといった理論的なフレームワークは、自然言語処理の分野だとあまり主流ではありません。そういうところも含めて間瀬さんたちの研究をどんどん取り込んでいって、よい形で研究に活かせたらなと思います。
――そういう意味では、日立では色んな領域の研究開発が行われているので、横のつながりからの応用もできそうですね。
間瀬 : まさにその通りですね。学術的に深めるということをやりながら、社内に広大な実証フィールドを持っています。近年はLumadaを中心に顧客共創プロジェクトもたくさん進めています。AIの研究をしてその成果をビジネスにつなげていく。この流れを一気通貫できる環境は、なかなか無いんじゃないかなと思います。
是枝:あとはやはり、僕たちが経験したように、海外で共同研究する機会があるのも非常に大きいなと思います。日立はスタンフォード以外にも様々な大学と共同研究プロジェクトを進めています。それらに参加できる機会が多いのは、研究者として非常に魅力的かなと思います。
最終的には、社会を変えるような大発見に携われるかもしれない

――おふたりの今後の目標としてはいかがでしょうか?
間瀬 : 目標ですか。もともと大きな夢がない人間でして、なかなか難しいですね。少し遡りますが、小学校の時の作文で、私は「大企業の研究所の研究員」に将来なりたいと書いていました。ゲームが好きだったこともあり人が楽しくなるようなコンピューターに携わりたいと思っていたようです。
現在はAIの研究者という立場ではありますが、あの頃から根底はあまり変わっておらず、人が豊かな生活を送れるようなコンピューターを社会に実装していきたいと思っています。
AIを研究するようになってよく思うことは、AIを使うことで今までの常識では考えられていなかったような「すごい発見」ができるんじゃないかなということです。物凄く大きなデータを扱いますし、人が最適だと思うもの以外が最適解だったということもあります。そういうものを突き詰めていくと、最終的には社会を変えるような大発見に携われるんじゃないかなと期待しています。
――すごく素敵ですね!是枝さんはいかがですか?
是枝:短期的な話としては、先ほどのデータセットをまだ公開したばかりなので、これから多くの研究者や企業の方々と一緒に、リーガルテックを盛り上げていきたいと思います。
また中長期的な夢について、そもそも私の研究動機は、「面倒くさいことが非常に嫌だ」というところから来ています。システムの無駄や日常生活のペインポイントなど、人生は自分のやりたいこと以外の無駄やイライラであふれているわけです。
もっと研究のことだけを考えて生きていきたいと思っているのですが、直近の5年を取っても、まだまだわだかまりはあります。
なかなか世の中が変わっていかないなと思いがあるので、社会へと還元していける研究をしていきたいなと思っています。
――そのために、これからどんな人と一緒に働きたいと思いますか?
是枝:手を動かせて、勉強することをやめない人ですかね。私も昔はQiitaをちょこちょこと書いていたのですが、そういった勉強を止めない人がいいですね。日立は企業規模が大きく、配置換えなどで研究環境も大きく変わりうる場所なので、自分で勉強していけないと厳しいと思います。
間瀬 : 新しい領域であっても、物怖じせずに飛び込んでいける。そういうマインドが非常に大事だと思っています。
私はもともとコンピューターサイエンス領域の研究者で数学はどちらかというと苦手でしたが、スタンフォード大学という世界でも有数の数学の天才が集まる環境に身を置いたことで、勉強しながら彼らとも数式の意味について議論できるようになっていきました。
またスキルアップ面だけでなく、元々の専門性を生かして、単純にプログラムを書くのが早いとかそういうこともありますし、実際の機械学習を現場に適用したときの知見について興味をもってもらったりと、自分が何者かという部分も少しずつ分かっていった気がしました。
要するに、異分野に飛び込むことで得られる学びはとても多いということです。
日立は事業領域が多く、様々な知見を合わせて提案していくことを日々繰り返すことになると思うので、それを楽しいと思ってくれる方となら一緒に働いていて楽しいなと思います。
――ありがとうございます。それでは最後に、読者の皆さまに向けて一言ずつメッセージをお願いします!
間瀬 : 今の時代、コラボとか共同研究など様々な形で一緒に働く機会があると思います。ぜひ本記事で興味を持ってくださった方と一緒に、AIを使って社会を豊かにしていく研究開発に取り組めたら嬉しいです。
是枝:このお話をいただく2年前は、シリコンバレーで共同研究をするとは夢にも思っていなかったのですが、ひょんなことからチャンスが来てスタンフォード大学に通っています。やりたいことがあれば、ずっと言い続けることが大事だと思います。
編集後記
XAIもNLPも、これからの高度情報化社会におけるAI活用を考える上では欠かせない技術領域だからこそ、そのような領域の最先端研究員が集まるスタンフォード大との共同研究が叶うのは、非常に魅力的な環境だと感じます。
特にインタビューでも議題に上がった、AI活用における「公平性」については定義が難しく、それ故に研究者以外も含めたマルチステークホルダーによる継続的な対話こそが重要であると、お話を伺いながら改めて感じた次第です。
日立製作所による海外機関との共同研究については、本記事以外にも多く取材しているので、ぜひ併せてご覧ください。
・ディープラーニングのゴッドファーザーのもとで、世界最先端のAI研究に没頭する日立の研究者に迫る
・海外共同研究から生まれたイノベーション。日立の研究者が、ドイツ人工知能研究で過ごした2年間に迫る。
・世界中のダークデータを抽出せよ。日立製作所 × スタンフォード大学の北米戦略について聞いてみた
取材/文:長岡武司
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
日立製作所の最新技術情報や取り組み事例などを紹介しています
コラボレーションサイトへ
日立製作所経験者採用実施中!
深層学習による自然言語処理技術に関する研究開発
募集職種詳細はこちら
信頼できるAI技術に関する研究開発
募集職種詳細はこちら
日立製作所の人とキャリアに関するコンテンツを発信中!
デジタルで社会の課題を解決する日立製作所の人とキャリアを知ることができます
Hitachi’s Digital Careersはこちら