「音声プラットフォームVoicyがTiDBを検証し採用に至るまで」Qiita Conference 2024イベントレポート

2024年4月17日〜19日の3日間にわたり、日本最大級(※)のエンジニアコミュニティ「Qiita」では、オンラインテックカンファレンス「Qiita Conference 2024」を開催しました。
※「最大級」は、エンジニアが集うオンラインコミュニティを市場として、IT人材白書(2020年版)と当社登録会員数・UU数の比較をもとに表現しています
当日は、ゲストスピーカーによる基調講演や参加各社のスポンサーセッションを通じて、技術的な挑戦や積み重ねてきた知見等が共有されました。
本レポートでは、株式会社VoicyのSRE バックエンドエンジニア・千田 航己氏によるセッション「音声プラットフォームVoicyがTiDBを検証し採用に至るまで」の様子をお伝えします。
※本レポートでは、当日のセッショントーク内容の中からポイントとなる部分等を抽出して再編集しています
登壇者プロフィール

SRE バックエンドエンジニア
システム的な観点からのVoicy

千田:本セッションでは、VoicyがTiDBを選定した経緯と、その際の検証内容をご紹介します。Voicyは音声コンテンツの総合プラットフォームを運営しており、昨年、メインのデータベースとしてTiDBの採用を決定しました。TiDBはMySQLと互換性のあるNewSQLデータベースとなっています。
選定の経緯としてVoicyがこれまで何に困っていたのか。検証内容として互換性が十分にあるのか、負荷に耐えられるだけのパフォーマンスが出せるのか、コストが予算内に収まるのか、といったことをご紹介していきます。

千田:まずはVoicyのサービス概要です。Voicyはスマートフォン1台で音声発信や聴取を楽しめる音声プラットフォームです。パーソナリティと呼ばれる発信者の方々が、収録専用のアプリ「Voicy Studio」を使って音声を収録して、リスナーはまた別の専用の再生アプリを使ってその話を聴く、というサービスです。発信側のチャンネル数は現在2,000以上、登録者は延べ200万人超となっております。
千田:こちらはVoicyで発信をされているパーソナリティの方々を、ごく一部掲載させていただいたものです。Voicyでは審査制を採用していて、通過率5%ほどの厳選された方々が発信をしてくれています。
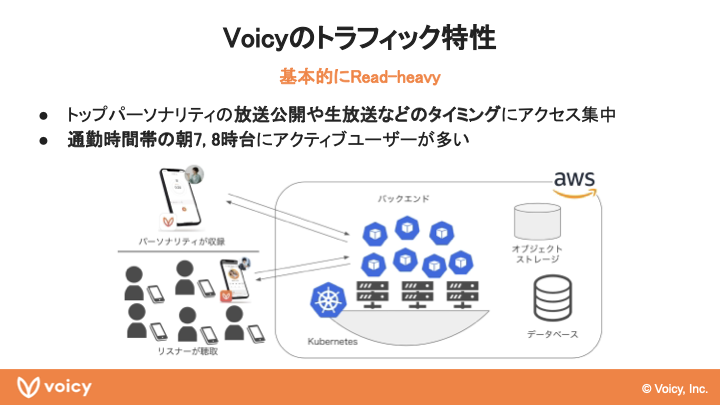
千田:続いてシステムの観点からVoicyを紹介します。Voicyのアーキテクチャをすごく簡略化した図にはなるのですが、先ほどご紹介した2種類のアプリがクライアントとなっていて、バックエンドのAPIはAWS上でKubernetesを使って動いています。Voicyのトラフィック特性については、特にフォロワーがたくさんいらっしゃるトップパーソナリティの方々が放送を公開されたり、生放送を開始/終了されたりするタイミングでアクセスが集中するといった特徴があります。
通勤時間帯の朝7、8時台にアクティブユーザーが多いのも、Voicyの特徴かなと思います。音声コンテンツはその特性上、何かをしながら聞くことができるので、朝の時間帯や出かける前の準備で家事をしているときとか、通勤の移動中といったタイミングで使われることが非常に多いです。
TiDBの概要
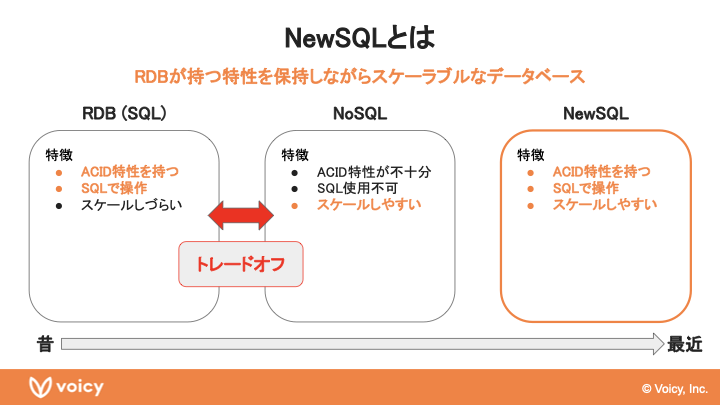
千田:ここからはTiDBの概要をご紹介します。「TiDBはNewSQLです」と最初にお話をしたのですが、NewSQLが何かをすごく簡単にまずは説明します。上の図では左に行くほど時代が遡り、右に行くほど比較的最近の潮流を表しています。リレーショナルデータベース(以下、RDB)が昔からよく使われていて、これはACID特性があるとか、SQLですごく柔軟な操作ができるといったことで、多くの場面で使われていました。しかしデータ量やトラフィックの増加時にスケールしづらいという特徴もありました。もちろん、スケールさせることが全くできないわけではないのですが、一定のノウハウが必要で難しさがあるといったデメリットがありました。
これに対して、RDBが持つような柔軟な特性全てを兼ね備えていないものの、スケールしやすい高負荷な環境でも使いやすいNoSQLを併用する流れが生まれてきています。RDBとNoSQLはトレードオフの特性を持っているので、これらを併用してシステムの要件に上手く対応していくというような流れです。その中で比較的最近生まれてきているのがNewSQLです。端的に言うと、RDBが持つ柔軟な特性を保持したまま、よりスケーラブルなアーキテクチャに乗ったデータベースと言えるかなと思います。

千田:続いてはTiDBの特徴です。TiDBはMySQL互換のNewSQLデータベースということで、アプリケーション開発者目線での使い心地がどうなのかというと、ほぼほぼMySQLと同じだと自分は感じています。
他の特徴としてスケーラブルな分散データベースというのがあって、分散システムになっていて今までのRDBよりもスケーリングが容易であったりとか、可用性が高くてTiDBのクラスターの一部のサーバーが落ちてしまったときも自動で復旧してくれるとか、そういった特徴があります。
またHTAP(Hybrid Transactional/Analytical Processing)という特性も持っていて、本日は詳しくはご説明しませんが、これまでRDBがメインで担っていたような通常処理(トランザクショナルな処理)と、データ分析的な処理(アナリティカルな処理)を一つのTiDBアーキテクチャの中で併せ持っているというものになります。
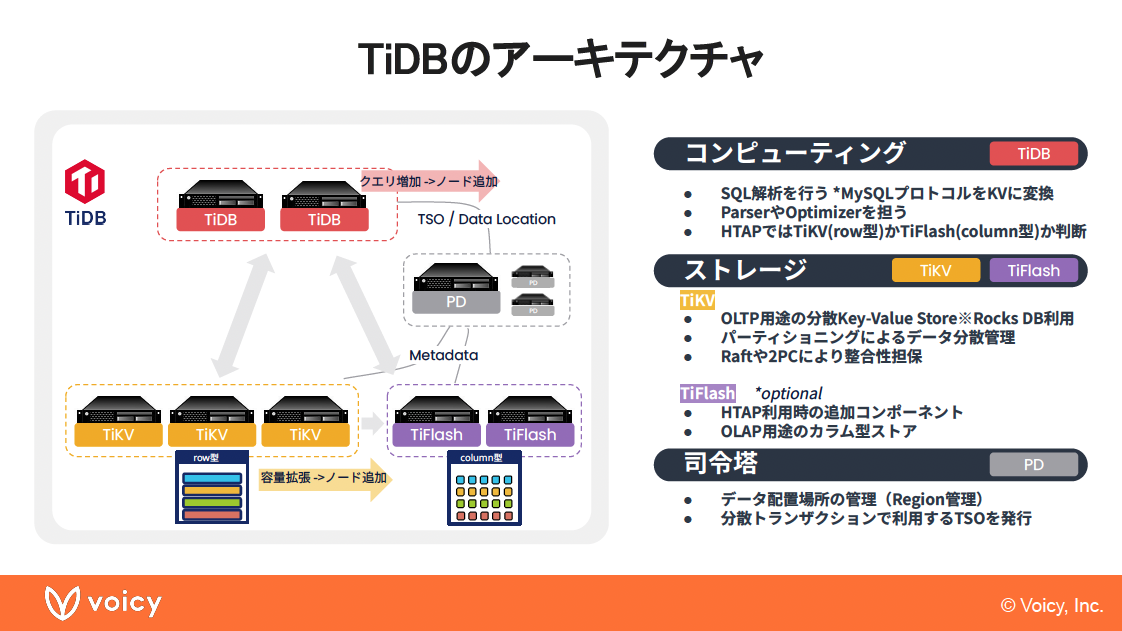
千田:TiDBのアーキテクチャは、このような感じになっています。簡単にお伝えすると、コンピューティング部分、ストレージ部分、司令塔と3種類に分かれていて、4つのコンポーネント(図の左側)があります。
この図全体がTiDBクラスターを構成しているのですが、その中でまずは一つ目、一番上が「TiDBノード」というコンポーネントになります。TiDBノードはクラスター全体のフロントエンド的な役割で、受け付けたSQLの解析を行ったり、その後「TiKV」と「TiFlash」という2つのコンポーネントがあるストレージ部分からデータを取り出すときの実行計画を立てたり、そういったことを行っています。
ストレージは2種類ありますが、基本的にデータはTiKV、名前の通りKey-Valueストアになっているんですけれども、こちらからデータが取ってくるものという風に考えて問題ないです。
先ほど、特別に集計処理のようなアナリティカルな処理を担当するコンポーネントも併せ持っているというお話をしましたが、それを担当しているのがTiFlashです。これがなくてもクラスター全体としては動くのですが、これを入れることによって処理がより効率的に行われるものがあるという風にご理解いただければと思います。司令塔部分に関しては、今回は説明を省略します。
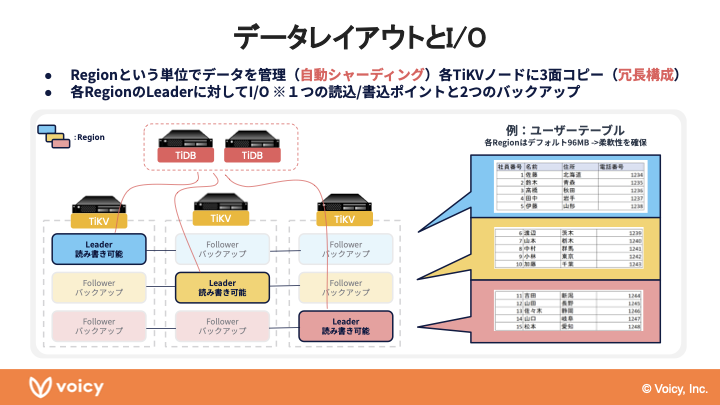
千田:次にTiDBのデータレイアウトとI/Oについて簡単にご紹介します。TiDBではデータをRegionという単位で管理しています。これはデフォルトで96MBのデータになっていて、図にあるように3つのノードにコピーを持っており、そのうち1つがLeaderで実際に読み書きが可能なもの、残りの2つがバックアップデータです。RegionごとにLeaderが配置されているノードがそれぞれ異なる構造になっていて、例えば青いものは一番左のTiKVノード、黄色いものは真ん中のノードに配置されていて、これによって読み書きの負荷の分散も図られています。ここまで少々駆け足ですが、Voicyのサービス概要とTiDBの概要の説明をしてきました。
VoicyがDB改善を検討した背景

千田:次にVoicyがデータベースの改善を行った背景について、お話しします。理由は大きく2つあり、1つ目はデータベースのコスト負担が大きくなってきていたこと、2つ目はサービス規模の今後の拡大に対応する必要があったことです。
ありがたいことに、Voicyはサービス開始からサービス規模が拡大していて、今後ももっと大きくなっていく想定なので、それに対応するためにデータベース側の改善も行いたいという背景があります。

千田:サービス規模の拡大に対してTiDBを使うメリットと、検証前に期待していたところが、上の画像に書いてある内容になっています。まずTiDBを使うと書き込みの負荷に対応しやすいと考えました。移行前はメインのデータベースとしてAmazon Auroraを使っており、今までは書き込みを行う場合にはwriterエンドポイントを使わないといけなくて、読み込みだけで良い場合はreaderエンドポイントを使うみたいなことを考える必要がありました。しかしTiDBにはwriterエンドポイント/readerエンドポイントという区別がないようなインターフェースになっているため、アプリケーション開発者の認知負荷を下げられる効果があるかなと思っています。
また書き込みに対して、スケールアウトで対応できるというポイントもあります。TiDB以外のデータベースの場合、読み込み用のリードレプリカを増やし、読み込みの負荷に対してサーバーの台数を増やすことで負荷分散ができても、書き込みに関しては書き込みを担当するサーバーが1台しかなくて、それに対して書き込みが増えてきた場合には、そのノード自体のスペックを上げることでしか対応できないケースがあります。ですがTiDBは、書き込みに対してもノード数を増やすことで対応できるということで、運用上の柔軟さもメリットになっていると感じます。
あと、先ほど簡単にお話しさせていただいたHTAPという特性によって、より効率的に処理できるものがあるのではないかという期待もありました。例えばリスナーの再生ログから再生数を集計するときに上手く動いたら嬉しいというような期待もありました。
NewSQLを検討するにあたって他にも選択肢はいくつかあるのですが、TiDBはMySQL互換ということで検証に進むハードルが低かったというポイントもあります。
TiDBの検証

千田:ここからは、VoicyがTiDBをどのように検証してきたのかについてご紹介します。検証の観点は次の3つ、パフォーマンス、コスト、ポータビリティです。
コストの観点

千田:まずはコストです。私たちは予算目標の設定を最初に行いました。予算を決めると、クラスター構成がそれに応じてだいたい決まってきます。どうしてこのような考え方をしたのかと言いますと、コストと、次に説明するパフォーマンスはトレードオフの関係になっているので、コストとパフォーマンスを両方とも変数として扱うと、その分検証パターンが肥大化してしまって大変です。なのでまずはコストを仮決めして、その上でパフォーマンスを検証していくという流れにしています。
パフォーマンスの観点
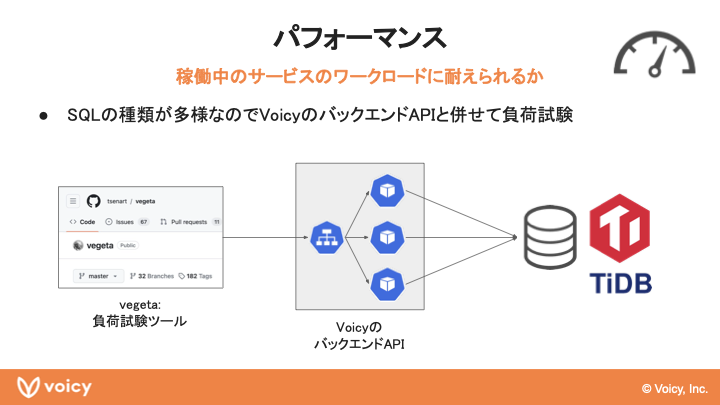
千田:パフォーマンスは、稼働中のサービスが本番のワークロードに耐えられるのかが観点になるのですが、今回の検証ではデータベース単体ではなく、Voicyで使われているバックエンドAPIと、バックエンドAPIをTiDBに繋いで(本番のワークロードをそのまま使ったわけではないですが)開発環境で使っているものをTiDBに繋ぎ、これと合わせてバックエンドAPIとTiDBをまとめて試験をするといったことを行いました。
もちろんデータベースの検証がしたいだけであればSQLをたくさん発行して「秒間何クエリさばけました」のような検証を行うパターンもあります。しかし今回のVoicyでは実際にAPI側から使って十分な性能が出るかというのを見たかったので、このような方法にしています。発行されるSQLが多様だったり、SQLごとに発行頻度も異なっているので、この形で検証することで実際に負荷に耐えられるかどうかを検証できると考えました。負荷試験ツールとしてはvegetaというGoで実装されているものを使っていますが、特段これじゃないといけないというわけではありません。

千田:実際どのようなシナリオを使ったのかについて、対象はAPIのピーク時に負荷が高いエンドポイントトップ10を取り出してきて、実際に本番でそのAPIが叩かれている秒間のリクエスト数を再現するような試験を行っています。例えば再生ログの記録が秒間40リクエストありますとか、チャンネル情報の取得に秒間10リクエスト来ていますみたいな、こういったものを実際のトラフィックから取ってきて再現するような負荷試験を行いました。こちらの表はそれを表現するイメージになっています。

千田:初回実行時の結果としては、本番同等までリクエスト数を上げていくと複数のスロークエリが観測されて、APIが正常に動作しないという結果になりました。これはもともと使っていたデータベースでパフォーマンスが出るようにSQLを書いているので、当然の結論だと考えられます。TiDBにとって不利な条件で実装されていると言い換えられるかもしれません。一回試してみた後にTiDB側をチューニングしていくということを行いました。

千田:行ってきたチューニングとして、代表的なものだけをかいつまんで紹介しています。ここに書いてあるものが全てではないのですが、例えば、いわゆる一般的なSQLチューニングとしてインデックスを追加するとか、キャッシュできる部分はキャッシュするとか。あと先ほどTiDBのアーキテクチャの部分でご説明したRegionの中で、一部の箇所にアクセスが集中してしまうみたいな問題に対処したりとか、そういったことを行っています。
またこのタイミングでスケールアウト、つまりTiDB側のクラスターを増強するということで、コスト側の微調整を加えてパフォーマンスの変化を見るといったことも併せて実施しています。

千田:パフォーマンスに関する最終結果としては、チューニングであったりとかその他の対応を続けていくことで、十分なパフォーマンスが見込めるという結論になりました。パフォーマンスチューニングする中で、NewSQLは魔法の技術ではないと、そういった感触を得ることができました。魔法の技術ではないのですが、十分に高性能で非常に優秀だという感覚をこのパフォーマンス検証の中で得られました。
またチューニングを行うときも、TiDB特有の設定みたいなものの比重は小さくて、先ほども紹介したような一般的なSQLチューニングを最初はやっていく方がインパクトが大きいということも分かりました。それをほとんどやりきった上で、特殊な部分にも手を付けていくみたいな感じです。あと感想レベルにはなりますが、今回の検証よりも大規模/高負荷な環境になっていくと、もっと真価を発揮していくんじゃないかなと感じています。
ポータビリティの観点

千田:最後に3つ目のポータビリティの検証になります。これは必要な機能であったり、互換性が十分にあるかといったことを検証しているんですけれども、VoicyのバックエンドのAPIが問題なく動くかを確認するといった検証になってます。Voicyでは毎週リグレッションテストという、Voicyサービスほぼ全体を網羅する、Voicyというサービスがきちんと動いてるかを確認するテストを実施しているんですけれども、それと同じケースを使って、TiDBに繋いだ状態で上手く動くかを確認しています。

千田:結果としては、ほとんど特別な対応をせずにリグレッションテストを通過しました。MySQLとの互換性が十分にあるということが確認できたと考えています。唯一エラーが起きたポイントとその時の対応については、SQL Modeという設定がMySQLにはありまして、これのデフォルト値がこれまでVoicyで運用していたよりも、TiDBがデフォルトで設定する値が少々厳格だったのでエラーが出て、それを若干緩めたという対応のみをしています。これはMySQLの設定の話で、TiDB特有の問題ではないので互換性に関しては問題ないかと思います。
一応補足として、VoicyではMySQLの機能を隅々まで使い切るような特殊なSQLをあまり書いていないので、そういった細かいところまで使い尽くしている場合ですと、差分が出てくる可能性はあるかもしれません。
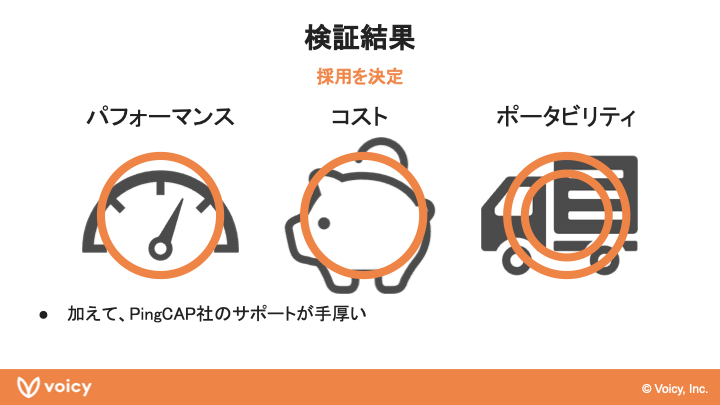
千田:最終的な検証結果として、パフォーマンスは十分にあり、コストも十分な範囲内、ポータビリティは十二分にあったということで、採用を決定しました。加えて、TiDBを提供しているPingCAP社のサポートが手厚いという点も大きかったです。プロダクトは良いけれどサポートがちょっと心配、というケースはたまにあると思いますが、TiDBに関してはこの部分も心配をせずに採用に踏み切れたと思っています。
さいごに

千田:発表としては以上になります。最後に告知ですが、「TiDB User Day」というイベントが今年の7月に開催されます。これは昨年私も参加したんですけれど、TiDBを使っている人やデータベースに興味がある人、またこれから学んでみたい開発者の方々、技術に興味がある方々が集まるイベントになっています。

千田:今年のTiDB User Dayでは、弊社の技術設計の責任者である山元が、今回の私のQiita Conferenceのセッションよりも深い内容をお話しする予定なので、興味を持たれた方はぜひご参加いただければと思います。以上で私からの発表を終わります、ありがとうございました!
取材/文:長岡 武司