クラウドの力を生かしてデジタルトランスフォーメーション(DX)を推進したいと考える企業が具体的にどこからどのように進めるべきか、その指針となるのが「Microsoft Cloud Adoption Framework for Azure」と、「Microsoft Azure Well-Architected Framework」です。Microsoft Cloud Adoption Framework for Azureがテクノロジ以外の領域も包含した包括的な企業戦略のガイダンスとなっているのに対し、Microsoft Azure Well-Architected Frameworkでは、Azure上の具体的な設計原則に落とし込んだ具体的な指針が示されています。
この記事では、「コスト最適化」「オペレーショナルエクセレンス」「パフォーマンス効率」「信頼性」「セキュリティ」というMicrosoft Azure Well-Architected Frameworkを構成する5つの柱のうち、信頼性について説明します。
落ちることを前提に、いかに稼働を継続するかを考える
クラウドは落ちないーー残念ながらそれは事実ではありません。確率は限りなく低くても、ダウンしてしまうことはあり得ます。むしろクラウドでは、個々のコンポーネントではダウンが起こることを前提に、システム全体の稼働をいかに継続させるかといった観点で考える必要があります。
多くの企業にとって問題となるのは「復旧手段がない状態でアーキテクチャがダウンすること」でしょう。そこで「いろいろな可能性を考え、それらからの復旧手段を用意しておくことが信頼性設計において重要なポイントになります。さらに、それをどうやってテストし、監視していくかについても定義していきます」と、マイクロソフトの第一アーキテクト本部 本部長、内藤稔氏は述べました。
信頼性の柱におけるポイントとしては、「信頼性構築タスク」「アプリケーションの設計」「バックアップと回復」「ビジネスメトリック」「カオスエンジニアリング」「データ管理」「監視と障害復旧」「リージョン全体でのサービスの中断から回復する」「回復テスト」の9項目が挙げられています。
信頼性構築タスクでは、要件の定義からデプロイ、監視など幅広いプロセスにまたがり、信頼性の高いアプリケーションを構築するためにどういった事柄に留意すべきかを示しています。
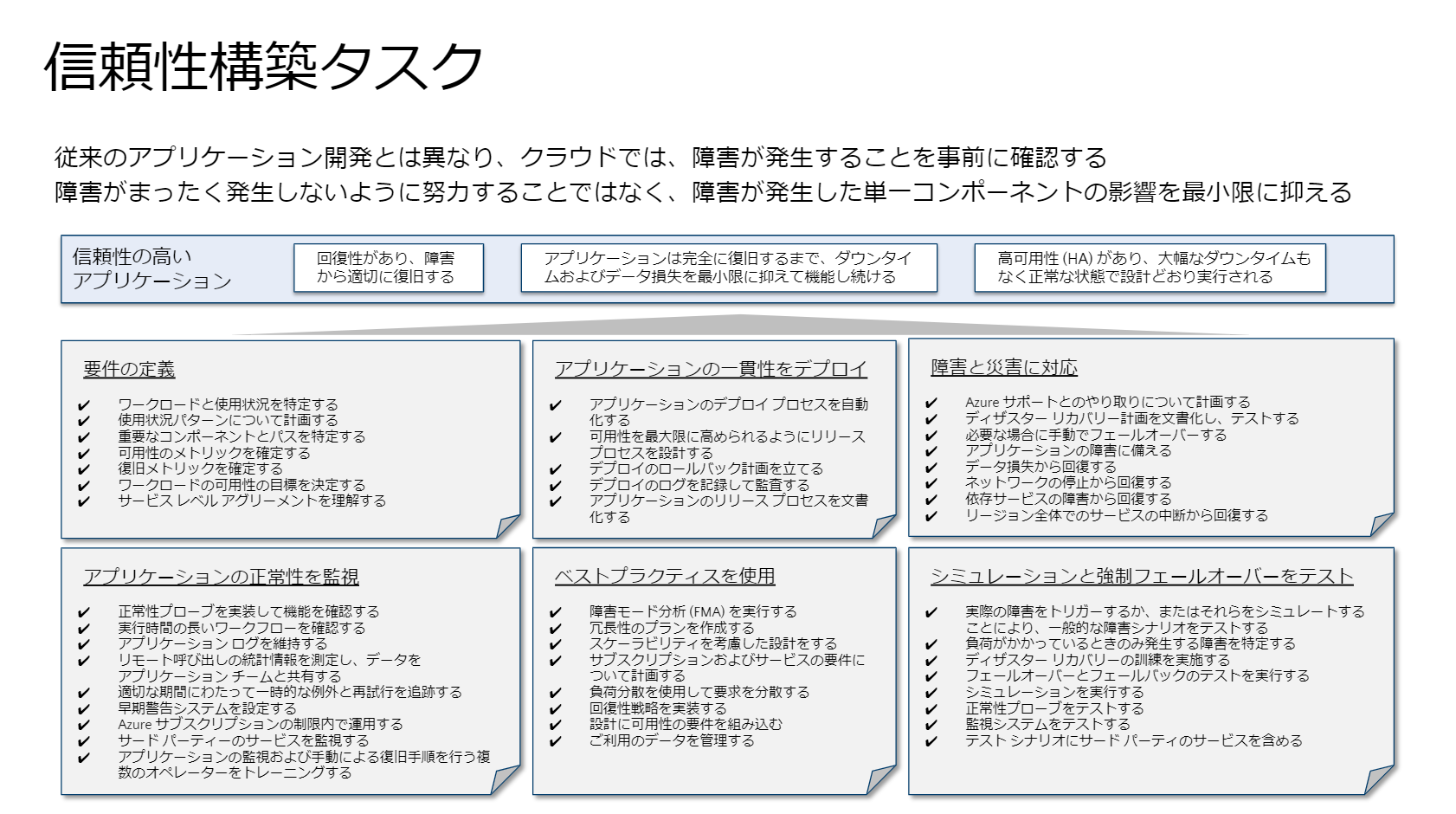
「クラウドといえども物理ハードウェアの集合体ですからもちろん障害はありますし、オンプレミスと同じようにアプリケーションの障害もあります」(内藤氏)。ですから障害が発生しないように努力する代わりに、障害が発生した単一コンポーネントの影響を最小限に抑えることを念頭に置き、クラウドならではのベストプラクティスを使ってほしいといいます。
またアプリケーションの信頼性を高めるには、つまりアプリケーションに回復性や可用性を組み込むには、やはり設計時からきちんと考えておく必要があります。あらかじめ回復性についての戦略を実装しておいたり、スケールアウト型で設計して負荷分散ができるようにし、高い回復性を持つ設計にするといった具合に、設計段階から考慮しておくことが重要です。

「特に分散システムの場合、どういう状況になったらエラーと判断し、どうなったら復旧させるかの基準を、それぞれきちんと考えておく必要があります」(内藤氏)
また、どこでどのような障害が起こりうるかを分析・特定する「障害モード分析」も有効です。Azureの主要なサービスごとに起こりうる障害モードの一覧と軽減手順について説明しているため、参考になるでしょう。
データ復旧の最後の砦、バックアップを適切に定義する
信頼性を確保する手段として不可欠なのがバックアップです。「データの復旧ができないと致命的な事態になってしまうことがあります。どんな障害が起こりうるか、それに対してどのようにデータを復旧させるのかを定義し、必要に応じてディザスタリカバリープランを組む必要があります」(内藤氏)

AzureではVMやストレージ、PaaS、さらには各アプリケーションごとにさまざまなバックアップ手法が定義されています。「利用するサービスの中でどのようなバックアップが可能かを理解し、実装に落とし込むことが重要です」(内藤氏)
この検討においては、RTOやRPO、MTTR、MTBFといった古典的な指標も含めたビジネスメトリックが重要です。「ビジネスとしてどのくらいまでならば停止を許容でき、どのくらいまでにデータを復旧させなければいいのか。どのくらいまでならばデータがまき戻ってもいいのか…そういったビジネスロジックや要件を理解した上ではじめて、システムに実装すべきバックアップが定義されることになります」(内藤氏)
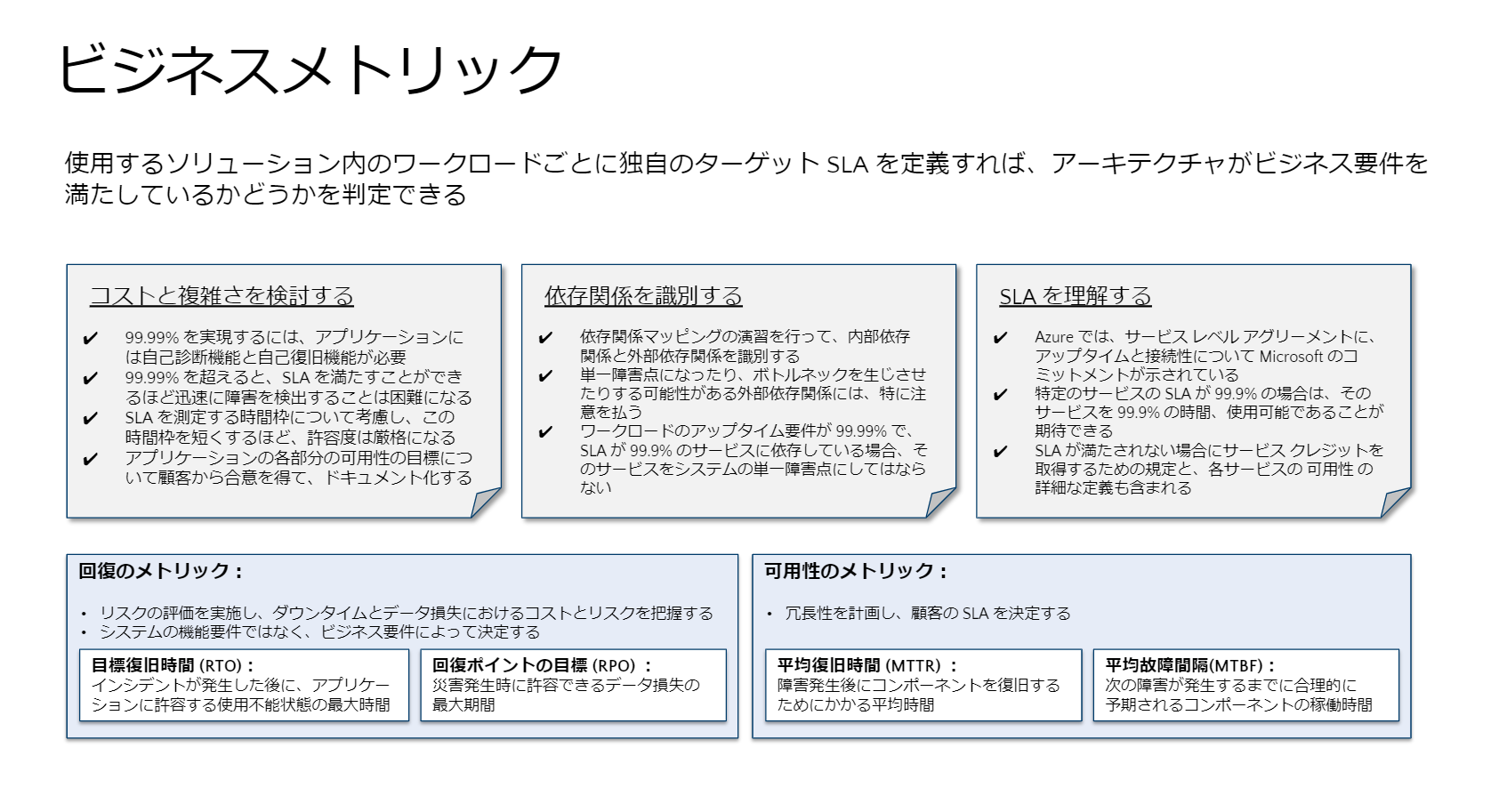
そしてAzureならではのポイントとして、SLAを理解しておくことの重要性を訴えました。サービスごとにどのようなSLAが設定されているか、つまりマイクロソフトがどこまで担保しているかを理解した上で実装していくと、適切なサービス設計につながるとしました。
Azureが提供するツールやサービスを理解し、適切な監視と復旧を
信頼性のためのポイントの中でユニークなのが、Netflixの事例でも有名になった「カオスエンジニアリング」でしょう。意図的に障害を発生させ、障害復旧プロセスがきちんと機能するかを検証するものですが、「可能であれば、本番環境も含め、運用テストの中で障害を起こしておくこういった手法を取り入れていくことも、システムの信頼性向上の手段として検討するといいと思います」と内藤氏は述べました。

逆に、当たり前すぎるほど当たり前のポイントが、監視と障害復旧です。内藤氏は「監視とは、障害の検出と同じではありません。監視によって、アプリケーション障害の全体像を把握することが必要です」とし、さまざまな監視ツールやメトリックを活用して「どこで何が起こるとどうなるのか」を全体的な視点で考えておく必要があるとしました。

Azureではそのための手段として、Application InsightsやLog Analyticsといったツールを用意しており、分析やアラートの生成が行えます。「こうしたツールをうまく使って、システムに応じた監視・障害復旧の手順を作っていただければと思います」(内藤氏)
またクラウドならではの利点として、複数のリージョンに分散するアプリケーションを作成することで、ある1つのリージョンで発生した障害がほかのリージョンに影響を与える可能性を抑え、サービス中断を回避できることが挙げられます。「どこまでリージョン障害を考慮するかはビジネス要件にもよりますが、仮想マシン、あるいはストレージ、SQLデータベースといったコンポーネントごとにそれぞれどのようにレプリケーションを行うか、検討しておくことが重要です」(内藤氏)
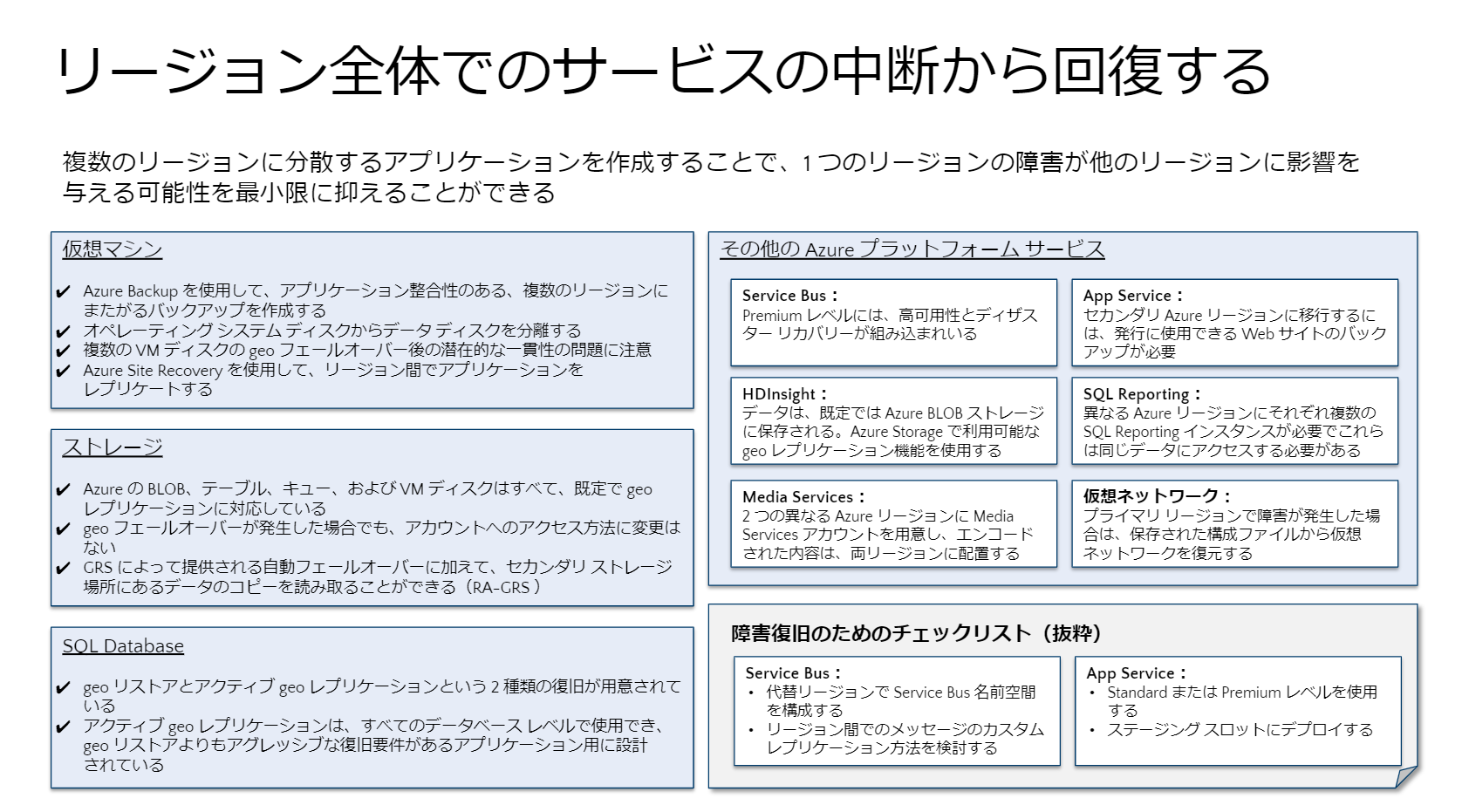
ここでも、サービスごとの特性を理解しておくことがポイントとなります。「Azureでは、マルチリージョンで、あるいはリージョン内でいろいろな復旧プランやサービスを用意しています。その内容を理解し、設計に入れ込むといいでしょう」(内藤氏)
そして、ほかの柱と同様ですが、やはりテストは欠かせないポイントです。「障害が起きた場合にどうやってそれを復旧させていくかのプロセスをきちんとテストしておくことが重要です。できれば定期的にそれを実施しておくといいでしょう」と内藤氏は述べました。

そして、チェックリストに挙げられている事柄を参照しつつ、信頼性を組み込んでよりよいシステムを実現してほしいと締めました。

文:高橋睦美